Summary
- https://github.com/Megvii-BaseDetection/BEVDepth
- BEVDepthの後継、軽量version
- 軽量なBEV-base Camera 3d detection
- CPUでも動作するレベルで軽量
- CPUでも数10msとかで動作、CUDAなら数ms
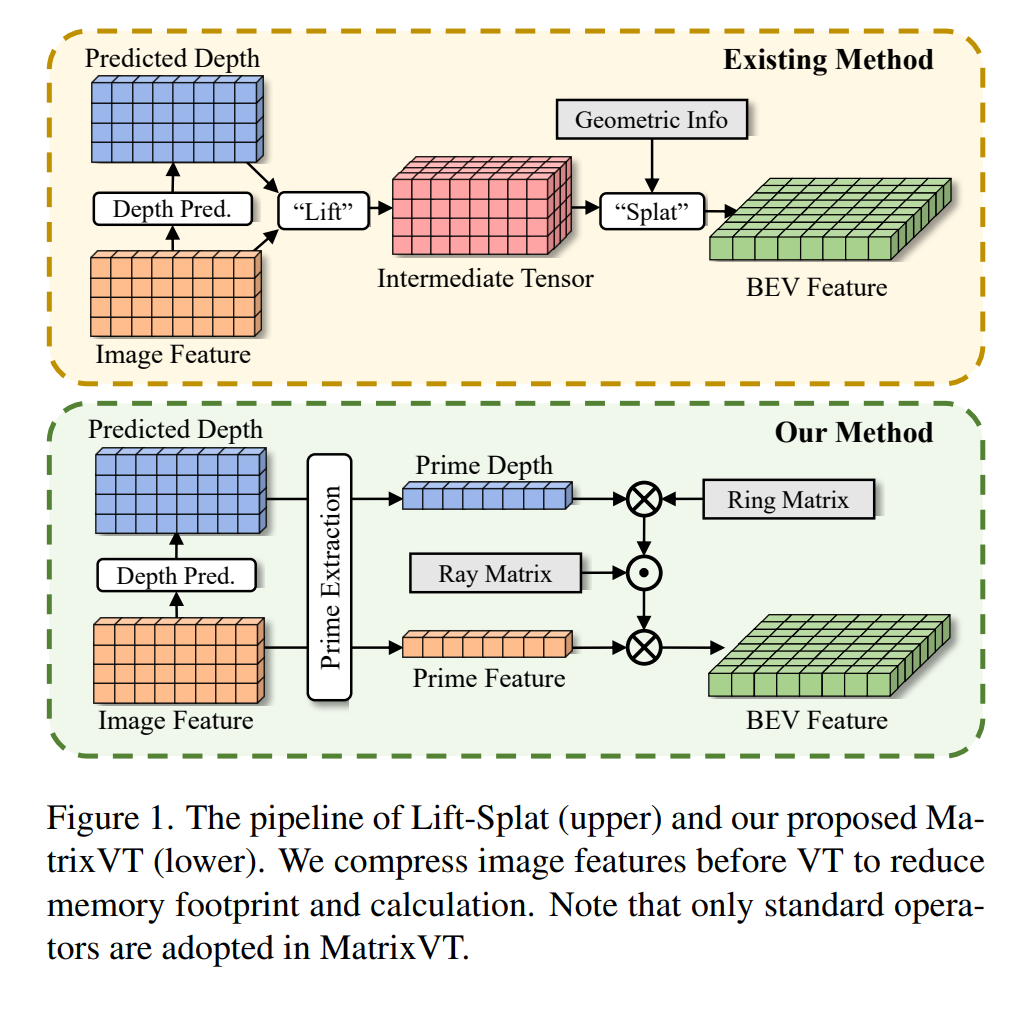
- contribution: Lift-Splat paradigm を活かしながら計算量を削減
- Prime Extraction, Ring & Ray Decomposition による 計算量の削減
- Feature Transportation Matrix (FTM) によるメモリ・計算量削減
Method
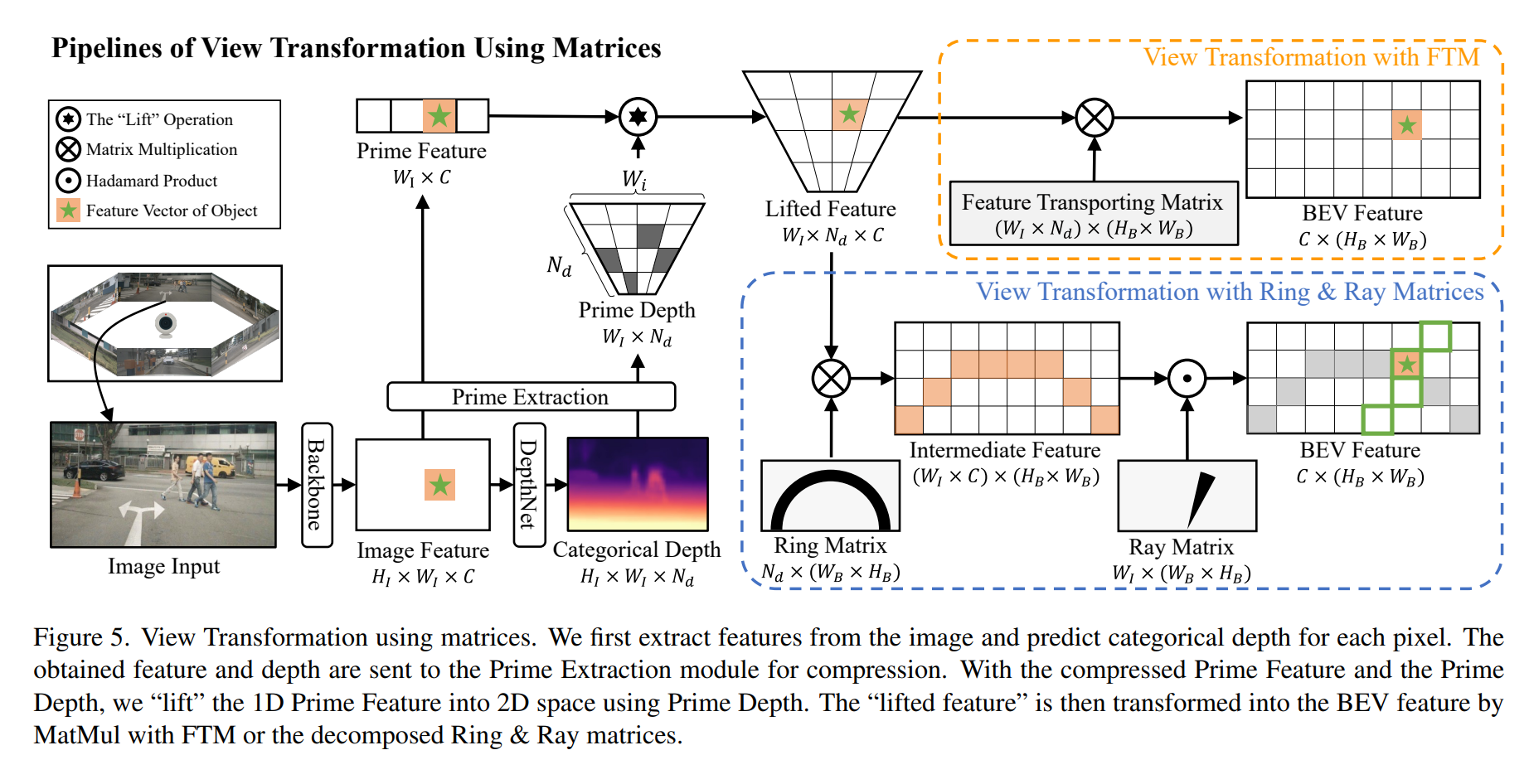
- 全体
- Backbone: extract image features
- DepthNet: a depth predictor is adopted to predict categorical depth distribution for each feature pixel to obtain the depth prediction.
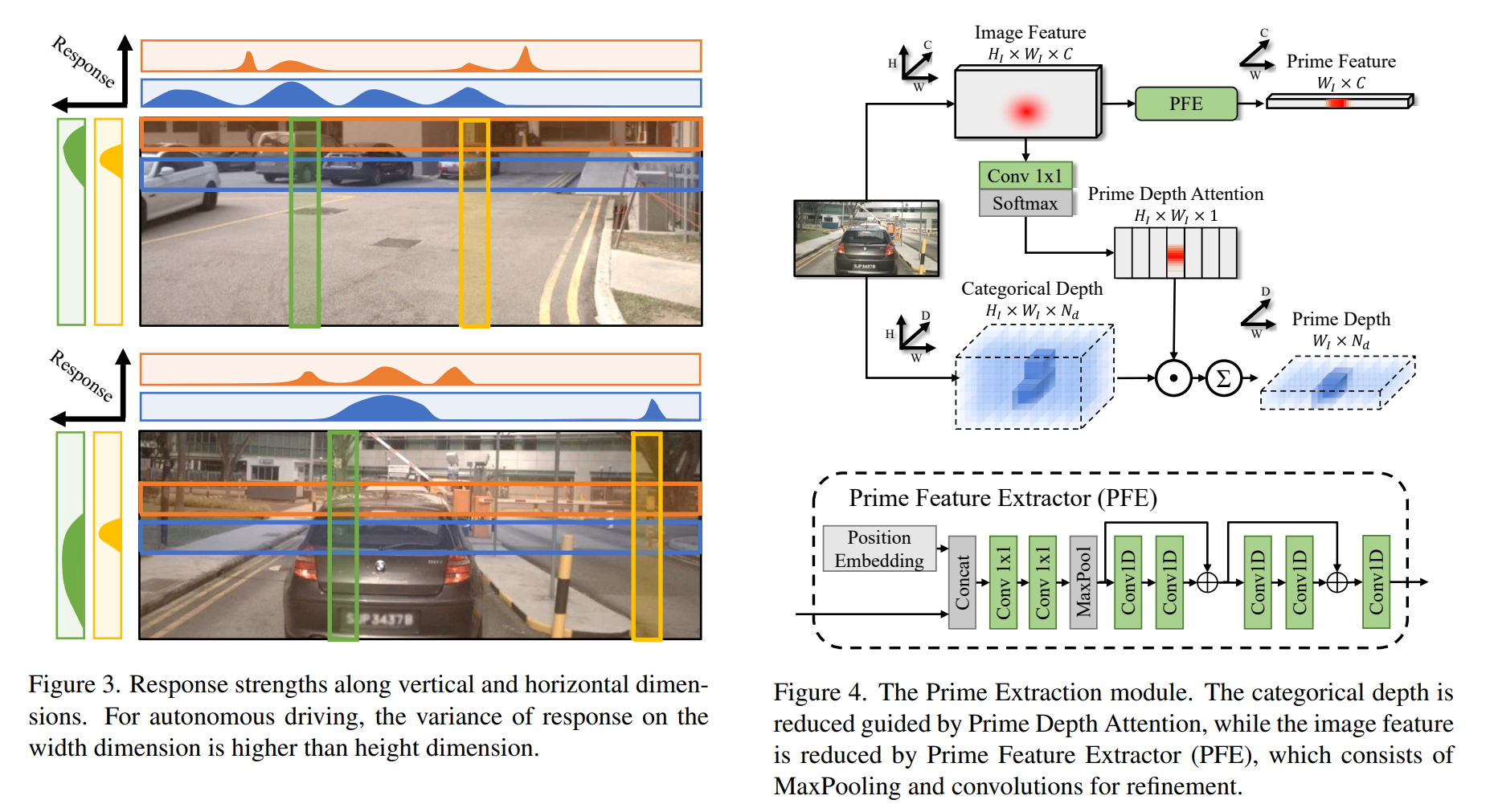
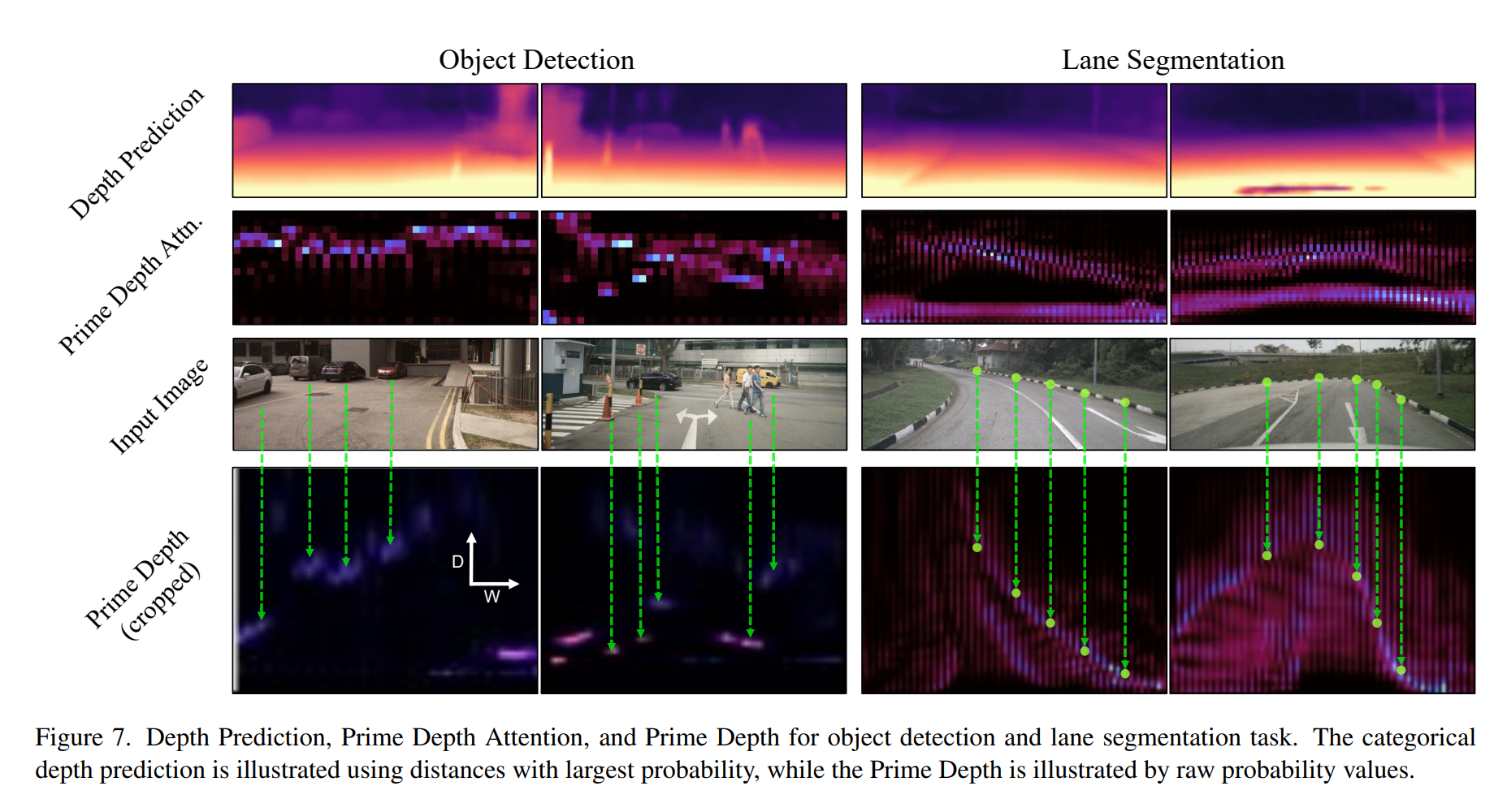
- Prime Extraction module: obtain the Prime Feature and the Prime Depth, which is the compressed feature and depth
- BEV Feature: Use by Prime Feature, Prime Depth, and the
pre-defined Ring & Ray Matrices
- 横の方がcontextを含んでいる
- Prime Feature Extractor (PFE) についての説明
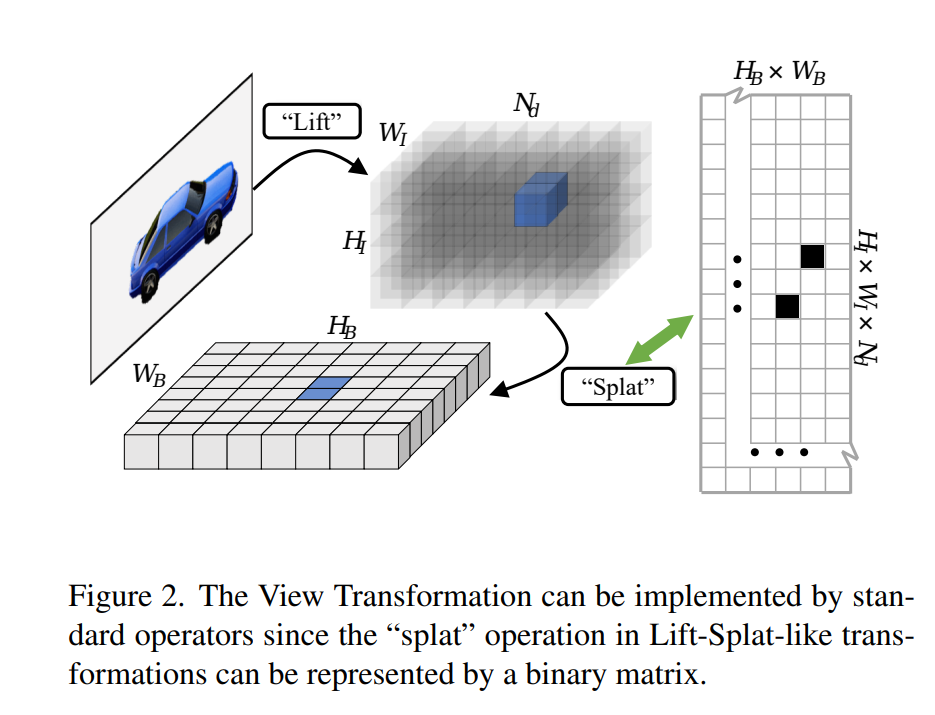
- “Ring and Ray” Decomposition
- a polar coordinate の考えを導入
- the image feature required for a specific BEV grid can be located by direction and distance
- 計算量の削減
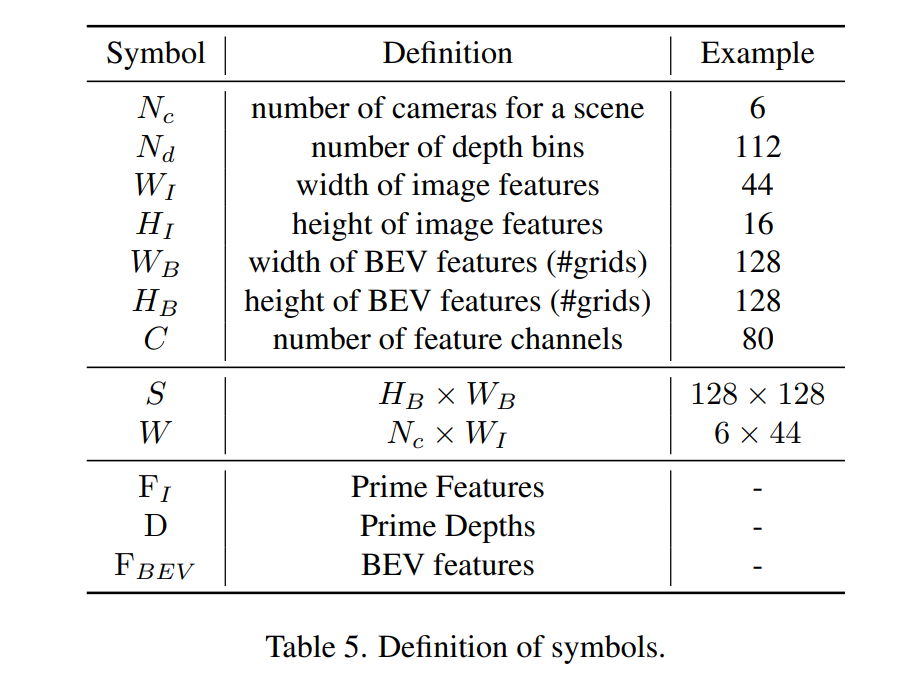
- from: WI × Nd × HB × WB
- to: (WI + Nd) × HB × WB
- 30 to 50 times 少ない
Experiment
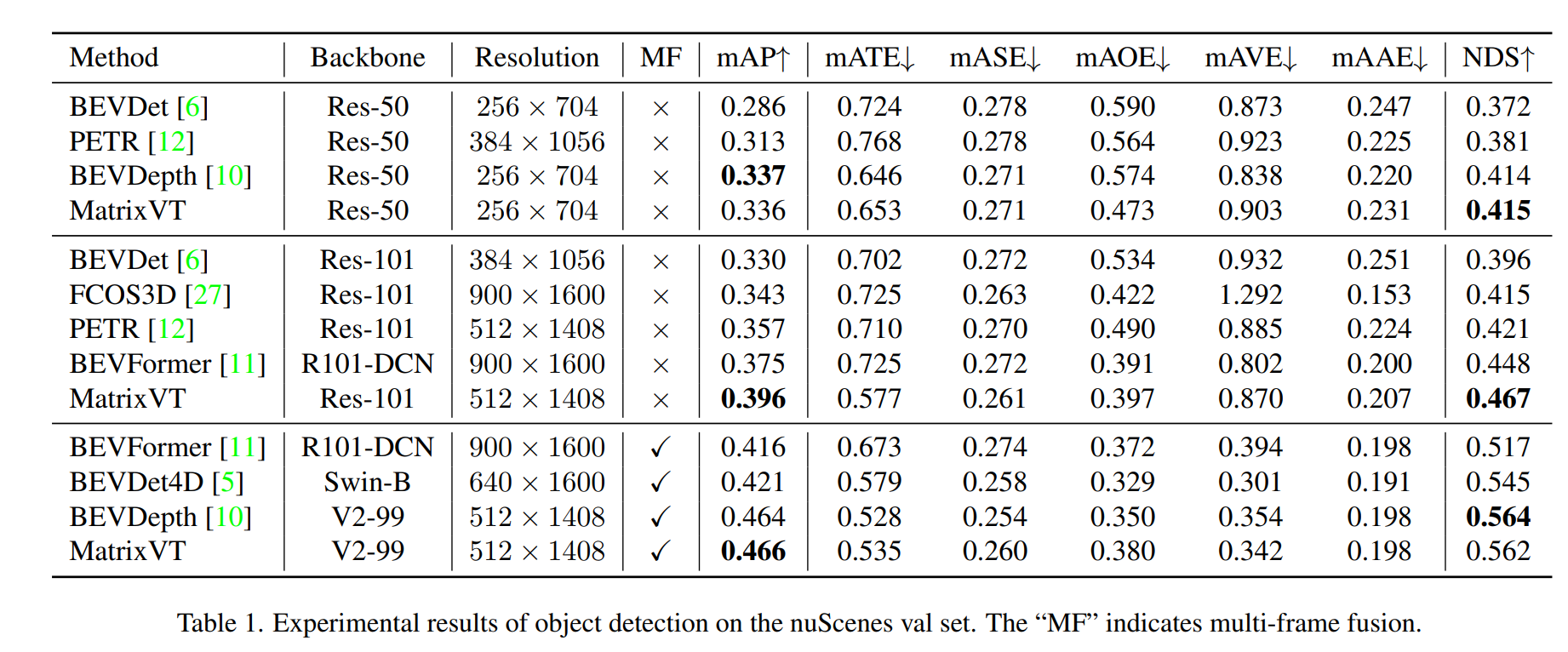
- Nuscenes val set
- test setじゃないのが気になる
- 汎化性能が犠牲になっている可能性はある
- BEVDepthと同じ性能を出せている
- Low resolution: Res-50 + BEV feature size 128 × 128, C= 80
- High resolution: V2-99 + BEV feature size 256 × 256, Cは不明
- MF = Multi frame fusion
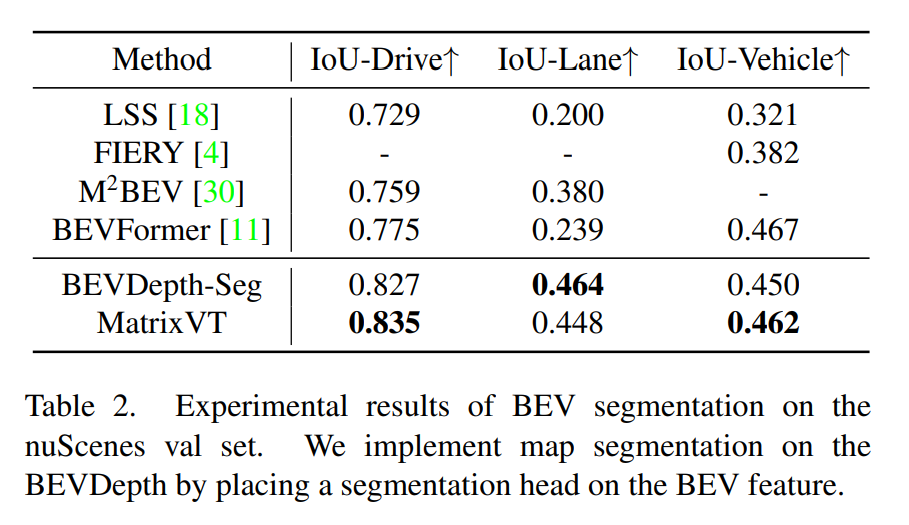
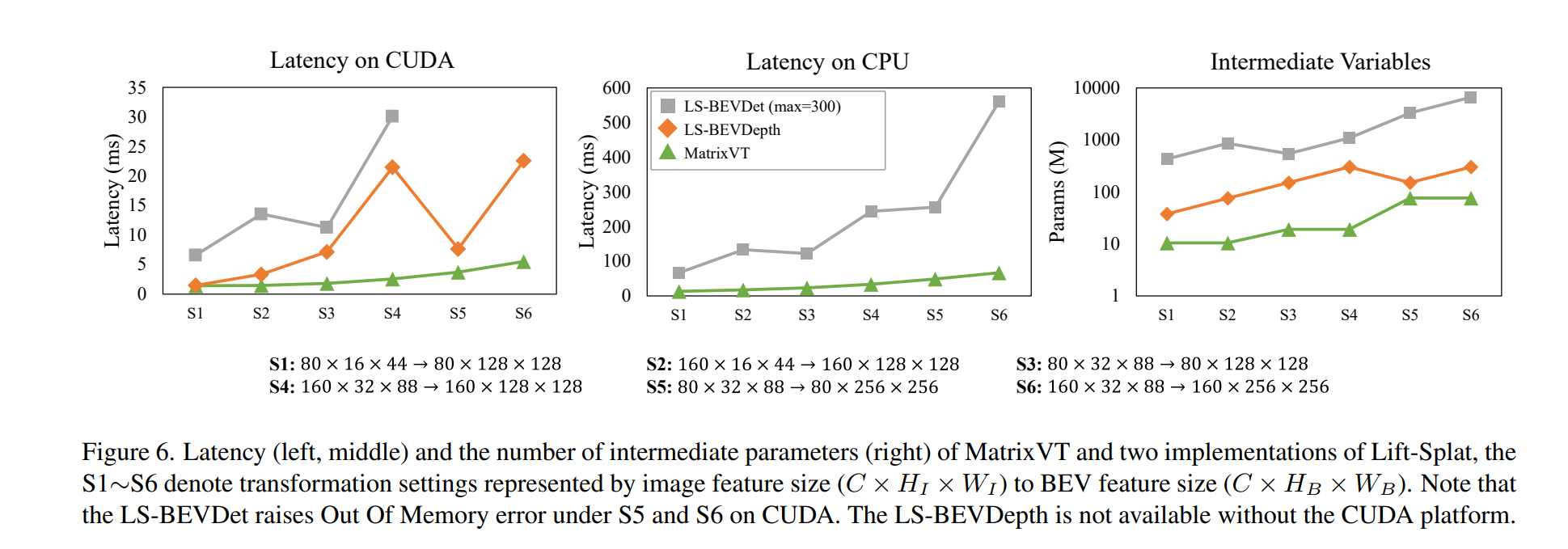
- 軽量化
- 恐らく上記の結果はC=80でS3
- CPUでも数10msとかで動作する
- CUDAなら数ms
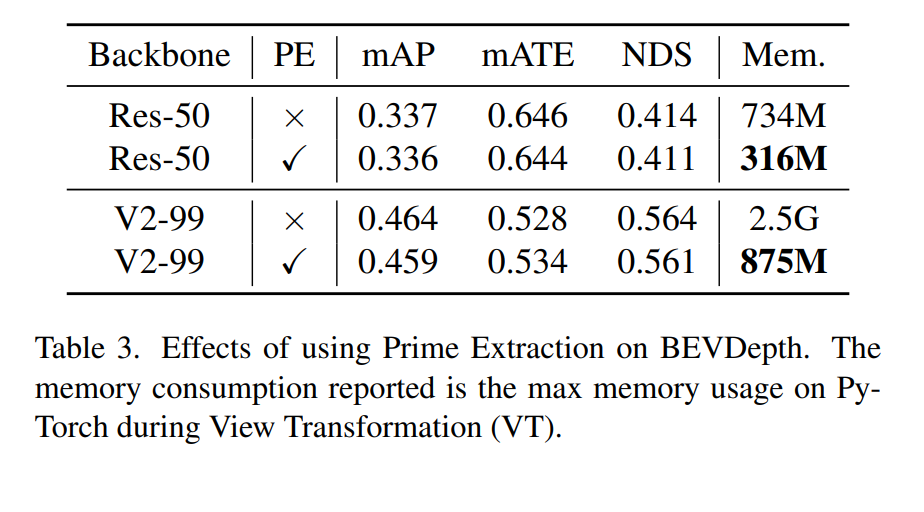
Discussion