Survey for Real-time 3D Detection in Autonomous Driving
Summary
In this blog, I summarize 3D detection methods, including implementation using inference optimization techniques like TensorRT.
Based on the performance comparison, following models of the multi-camera 3D detection stand out:
- StreamPETR (ResNet50): This is a lightweight model, making it suitable for a wide range of applications.
- StreamPETR (ResNet101): This model strikes a good balance between detection performance and inference time.
- Far3D (V2-99): This model may be too computationally heavy for certain environments. So it may be more appropriate as offline model.
Based on the performance comparison, following models of the LiDAR-based 3D detection stand out:
-
CenterPoint (pillar): The backbone of Pillar encoder is stable in TensorRT environment, so it is suitable for a wide range of applications.
-
TransFusion-L (spconv): This model has a moderate balance between detection performance and inference time.
-
BEVFusion-CL (spconv+ResNet50): This model uses both camera images and LiDAR pointcloud. If your system can reliably obtain the sensor data, it may be suitable.
-
Summary of Table
- The values in italics are estimated.
- Mo.: Modality of input (C = Camera input, L = LiDAR input).
- mAP-Nv: mAP on Nuscenes validation set (fp32, PyTorch).
- mAP-Nt: mAP on Nuscenes test set (fp32, PyTorch).
- mAP-Av: mAP on Argoverse validation set (fp32, PyTorch).
- TensorRT: Inference time and GPU memory by TensorRT (RTX3090, fp16).
- Note that the time delay also increases as the resolution of the camera input increases.
| Model | Mo. | mAP-Nv | mAP-Nt | mAP-Av | TensorRT |
|---|---|---|---|---|---|
| StreamPETR (ResNet50) | C | 43.2 | 14ms | ||
| StreamPETR (V2-99, 320*800) | C | 48.2 | 32ms | ||
| Far3D (V2-99) | C | 24.4 | 100ms | ||
| CenterPoint (pillar) | L | 48.4 | |||
| CenterPoint (spconv) | L | 59.5 | 60.3 | 27.4 | 10ms |
| TransFusion-L (spconv) | L | 64.9 | 10ms | ||
| BEVFusion-CL (spconv+ResNet50) | CL | 67.9 | 15ms |
Performance Analysis
Performance
- Table for performance
- Pre.: Pretrain model
- Ten.: TensorRT(C++) implementation
- Mo.: Modality of input (C = Camera input, L = LiDAR input).
- mAP-Nv: mAP on Nuscenes validation set (fp32, PyTorch).
- mAP-Nt: mAP on Nuscenes test set (fp32, PyTorch).
- mAP-Av: mAP on Argoverse validation set (fp32, PyTorch).
- PyTorch: Inference time for Nuscenes data by PyTorch (RTX3090, fp32).
- TensorRT: Inference time and GPU memory by TensorRT (RTX3090, fp16).
| Model | Pre. | Ten. | Mo. | mAP-Nv | mAP-Nt | mAP-Av | PyTorch | TensorRT | TensorRT other |
|---|---|---|---|---|---|---|---|---|---|
| BEVFormer tiny (ResNet50) | Yes | Yes | C | 25.2 | 62ms | 14ms, VRAM 1.7GB | 26ms (RTX3090, fp32) | ||
| BEVFormer small (ResNet101) | Yes | Yes | C | 37.5 | 40.9 | 196ms | 78ms, VRAM 3.7GB | 151ms (RTX3090, fp32) | |
| BEVFormer base (ResNet101) | Yes | Yes | C | 41.6 | 44.5 | 417ms | 555ms, VRAM 11.8GB | 666ms (RTX3090, fp32) | |
| BEVFormer (V2-99) | C | 48.1 | |||||||
| StreamPETR (ResNet50) | Yes | Yes | C | 43.2 | 36ms | 33ms (Orin) | |||
| StreamPETR (ResNet101) | C | 50.4 | 156ms | ||||||
| StreamPETR (V2-99, 320*800) | Yes | C | 48.2 | 80ms | |||||
| StreamPETR (V2-99, 960*640) | C | 20.3 | |||||||
| StreamPETR (V2-99, 640*1600) | C | 55.0 | |||||||
| StreamPETR (ViT-L) | C | 62.0 | |||||||
| Far3D (ResNet101) | C | 51.0 | |||||||
| Far3D (ViT-L, 1536*1536) | C | 63.5 | |||||||
| Far3D (V2-99, 960*640) | Yes | Yes | C | 24.4 | 366ms (Orin, fp16) | ||||
| CenterPoint (pillar) | Yes | Yes | L | 48.4 | |||||
| CenterPoint (spconv) | Yes | Yes | L | 59.5 | 60.3 | 27.4 | 80ms | 10ms, VRAM 1.4GB | 43ms (Orin, fp16) |
| TransFusion-L (spconv) | Yes | Yes | L | 64.9 | 67.5 | 80ms | 10ms, VRAM 1.5GB | ||
| TransFusion-CL (spconv) | Yes | CL | 68.9 | 156ms | |||||
| BEVFusion-CL (spconv+Swin-T) | Yes | Yes | CL | 68.5 | 70.2 | 119ms | 20ms | ||
| BEVFusion-CL (spconv+ResNet50) | Yes | Yes | CL | 67.9 | 15ms, VRAM 3GB | 55ms (Orin, fp16) |
Comparison of Models
In this section, I estimate Inference Speed of TensorRT with RTX3090.
We can compare Pytorch(RTX3090) and TensorRT (RTX3090, fp16) from
- BEVFormer small (ResNet101) TensorRT (RTX3090, fp16): 78ms
- BEVFormer small (ResNet101) PyTorch (RTX3090): 196ms
We can compare TensorRT (Oirn, fp16) and TensorRT (RTX3090, fp16) from
- BEVFusion-CL (spconv+ResNet50) TensorRT (RTX3090, fp16): 15ms
- BEVFusion-CL (spconv+ResNet50) TensorRT (Orin, fp16): 55ms
From these comparison, we can estimate as follows.
- StreamPETR (ResNet50) TensorRT (RTX3090, fp16): 36ms * (78ms / 196ms) = 14ms
- StreamPETR (ResNet50) PyTorch (RTX3090): 36ms
- StreamPETR (V2-99, 320*800) TensorRT (RTX3090, fp16): 80ms * (78ms / 196ms) = 32ms
- StreamPETR (V2-99, 320*800) PyTorch (RTX3090): 80ms
- StreamPETR (ResNet101) TensorRT (RTX3090, fp16): 156ms * (78ms / 196ms) = 62ms
- StreamPETR (ResNet101) PyTorch (RTX3090): 156ms
- Far3D (V2-99) TensorRT (RTX3090, fp16): 366ms * (15ms / 55ms) = 99.8ms
- Far3D (V2-99) TensorRT (Orin, fp16): 366ms
Backbone Models
VoVnet
VoVnet is used for image encoder of image method. “V2-99” means image encoder of VoVNet-99.
- Implementation
Sparse Convolution
Sparse convolution is used for LiDAR pointcloud encoder. Sparse convolution improves the efficiency and scalability of segmentation tasks on sparse 3D data. Because Sparse Convolution is both efficiency and high performance, the backbone of Sparce Convolution is used for many models. Note that the library of Sparse Convolution often has the issue related to CUDA environment, so if the system like OS are unstable (update many times including CUDA version), I cannot recommend to use Sparse Convolution.
- Implementation:
PointPillars
PointPillars is first standard model as LiDAR-based 3D object detection. PointPillars represents a breakthrough in real-time 3D object detection by efficiently encoding LiDAR point clouds into a structured grid and using fast 2D convolutions to process them. Since Pillar Feature Net is efficient backbone, so it has been used for many models. Note that TensorRT implementation of Pillar Feature Net is more stable than Sparse Convolution.
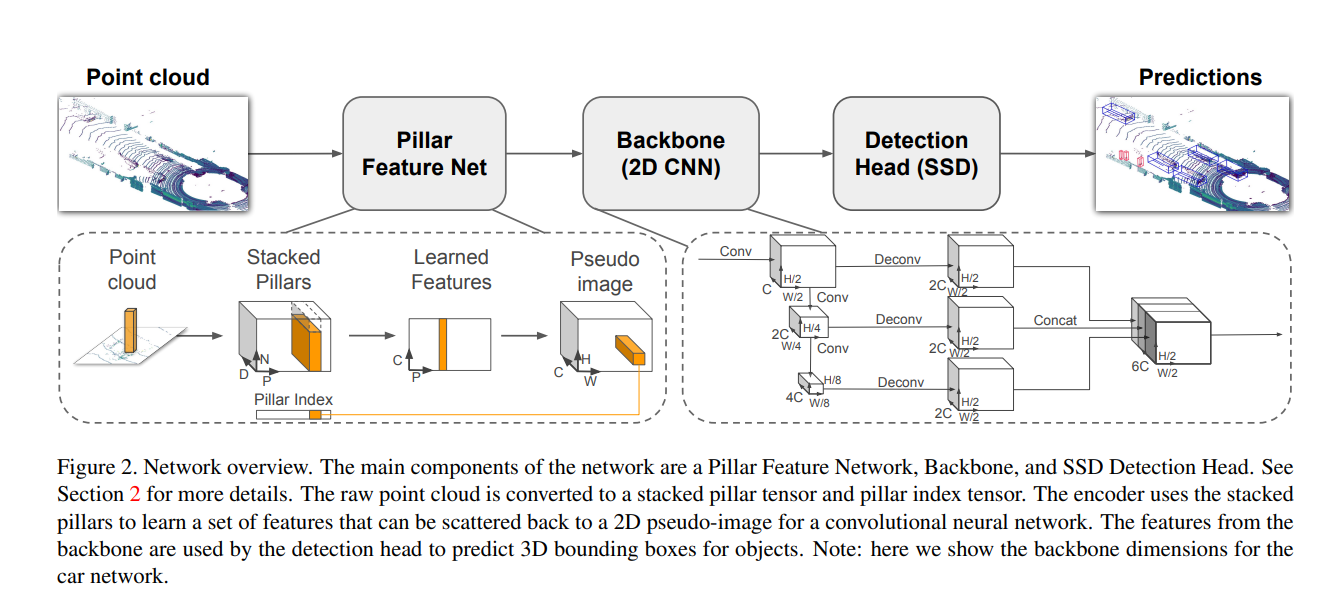
- Implementation:
Camera-based Models
BEVFormer
The BEVFormer framework offers 3D detection based on Bird’s-Eye View (BEV) representations for autonomous driving systems using multi-camera inputs and spatiotemporal transformers.
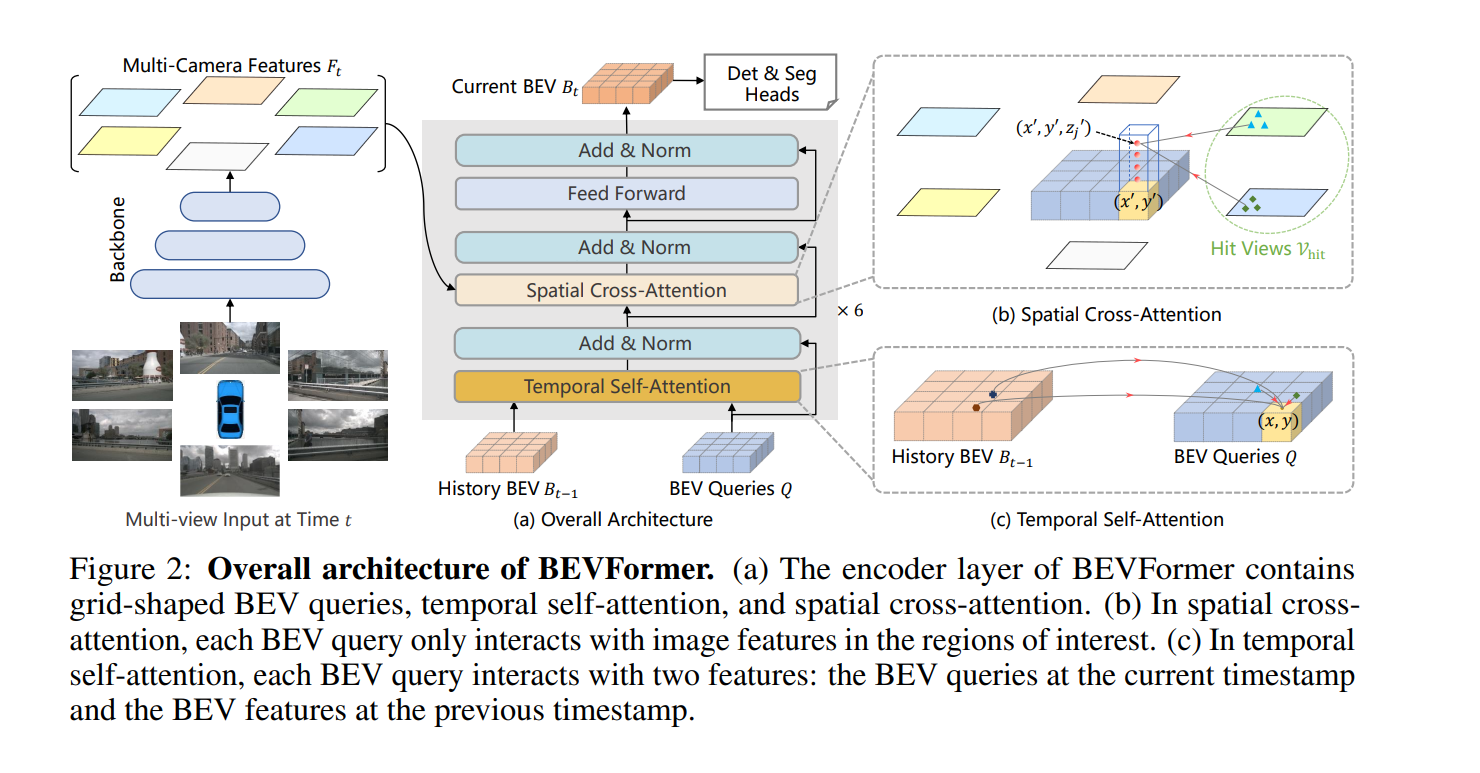
StreamPETR
StreamPETR introduces an object-centric temporal modeling approach for multi-view 3D object detection, offering a more efficient and scalable solution. This is particularly useful for autonomous driving, where real-time performance and high accuracy are essential.
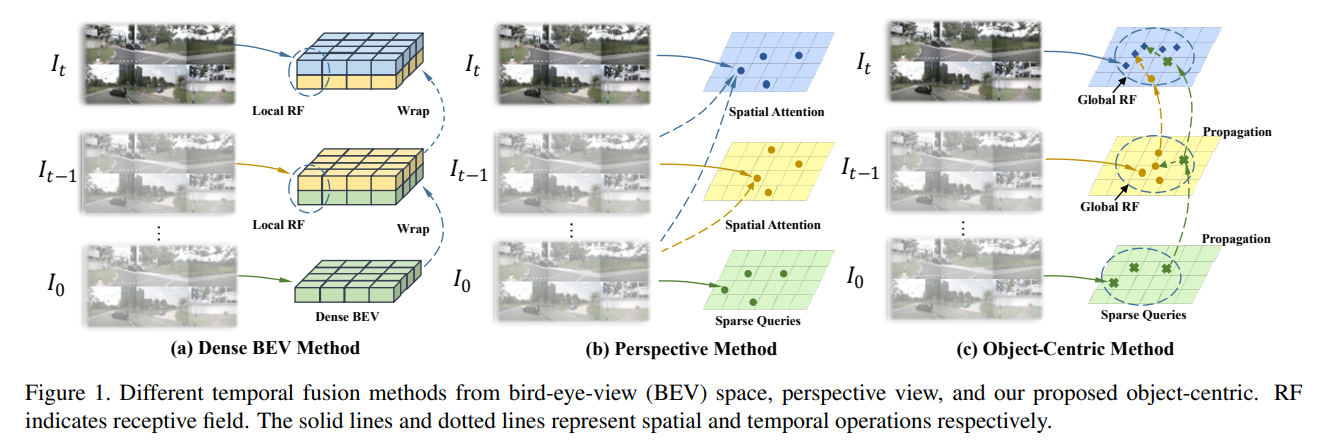
- My blog (Japanese)
- Implementation:
Far3D
Far3D provides a significant advancement in surround-view 3D object detection by expanding the detection horizon to include distant objects.
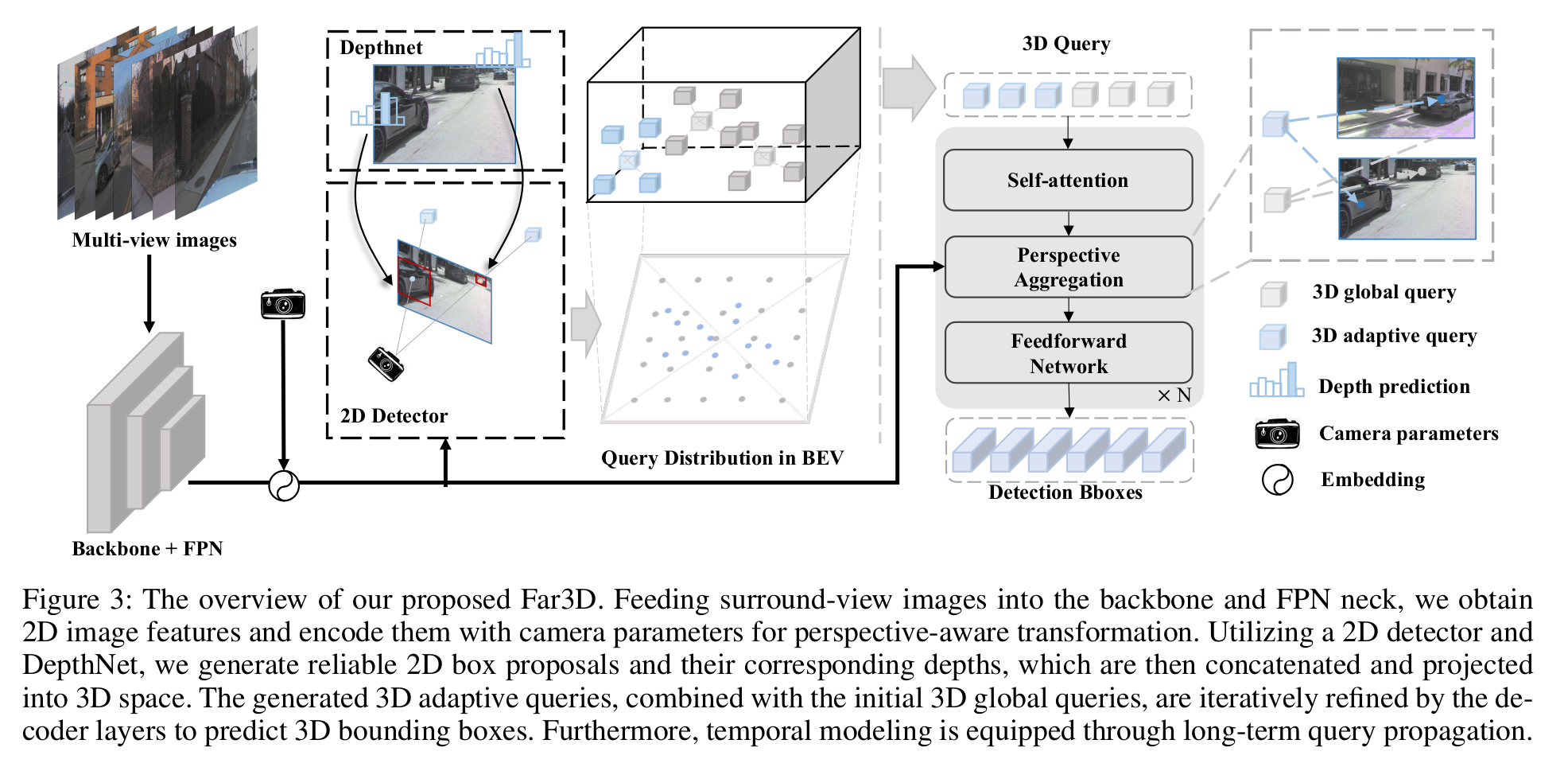
- My blog (Japanese)
- Implementation:
LiDAR-based Models
- Comparison with each class
- The threshold for class AP is 1.0m of the center distance.
- CenterPoint
- TransFusion-L
| Car | Truck | CV | Bus | Tra | Bar | Mot | Bic | Ped | Cone | |
|---|---|---|---|---|---|---|---|---|---|---|
| CenterPoint (spconv) | 84.5 | 47.9 | 7.9 | 58.9 | 28.1 | 62.4 | 44.1 | 16.0 | 76.3 | 51.9 |
| TransFusion-L (spconv) | 87.7 | 59.7 | 19.3 | 72.8 | 40.9 | 70.0 | 72.0 | 54.7 | 86.5 | 73.9 |
| BEVFusion-CL (spconv) | 88.3 | 53.6 | 21.8 | 73.3 | 38.1 | 72.4 | 76.2 | 61.2 | 87.4 | 78.0 |
CenterPoint
CenterPoint is a simple and efficient model for 3D detection, often considered the standard in autonomous driving. CenterPoint can choose from spconv (Sparse Convolution) or pillar (Pillar Feature Net) as backbone of LiDAR encoder.
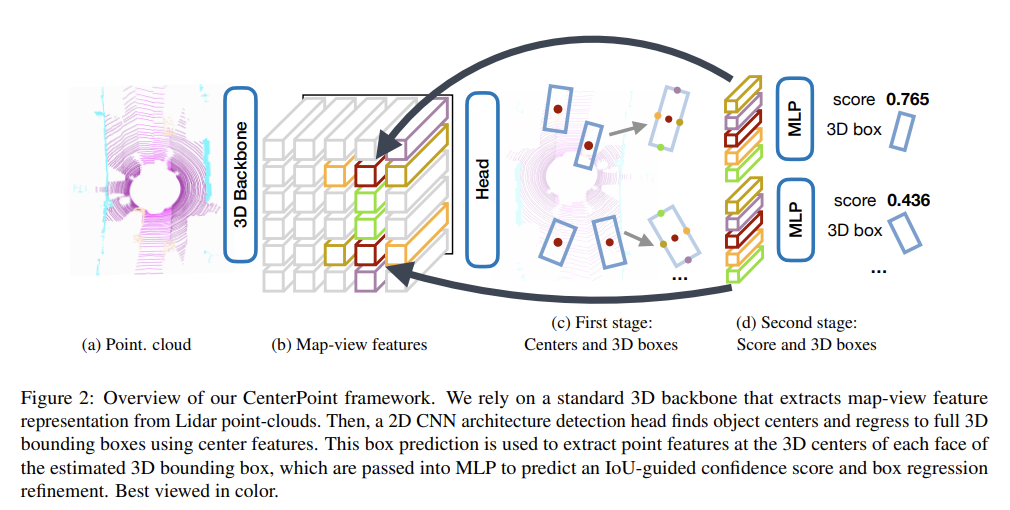
- My blog (Japanese)
- Implementation:
- mmdetection3d implementation
- TensorRT implementation
- ROS2 implementation
- Note that this implementation is based on pillar backbone.
TransFusion
TransFusion introduces Camera-LiDAR fusion for 3D object detection using a transformer-based architecture and a cross-modal attention mechanism. While Camera-LiDAR fusion is not efficient results, the LiDAR-only method using TransFusionHead is an efficient model. TransFusion can choose from spconv (Sparse Convolution) or pillar (Pillar Feature Net) as backbone of LiDAR encoder.
![]()
- Implementation:
- Official implementation
- mmdetection3d implementation (LiDAR-only method)
- TensorRT implementation for LiDAR-only method
- ROS2 implementation
- Note that this implementation is based on pillar backbone.
BEVFusion
BEVFusion introduces a robust and efficient framework for multi-sensor fusion in autonomous systems. By leveraging a unified Bird’s-Eye View (BEV) representation, the framework simplifies and improves the process of combining data from various sensors (LiDAR, cameras, radar) while supporting multiple tasks such as object detection, tracking, and segmentation in a single pipeline. BEVFusion use spconv (Sparse Convolution) as backbone of LiDAR encoder and ResNet or SwinTransformer as backbone of image encoder.
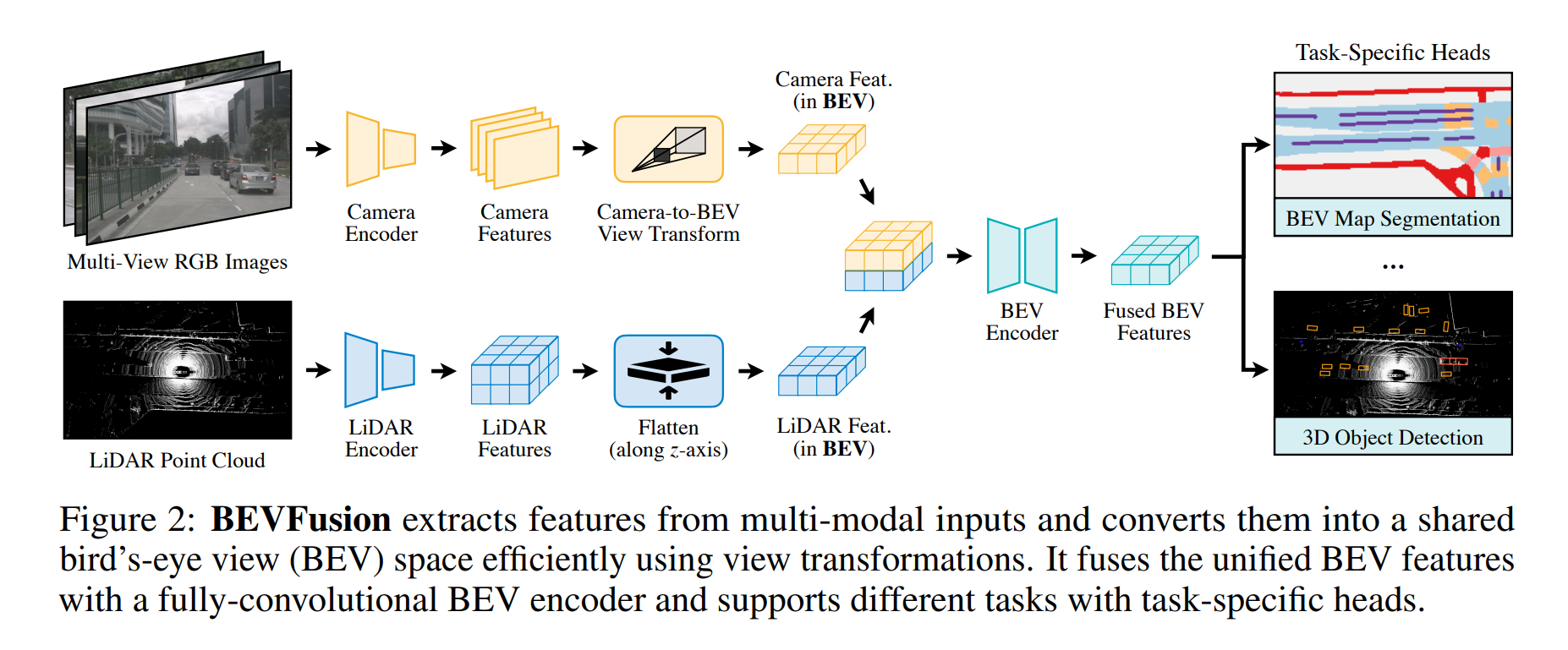
- My blog (Japanese)
- Implementation:
- Official implementation
- mmdetection3d implementation
- TensorRT implementation
- ROS2 implementation
- Note that this implementation is based on spconv backbone.