Summary
- Link
- Two-stage型 Lidar 3d multi-class detection framework
- “multi-view” = “perspective view” + BEV
- “perspective view” baseのsemantic segmentation : Range imageのこと
- drivable spaceも計算できるsemantic segmentation
- BEV base のdetectction and classify objects
- 2D*2stageで3d detectionを行うframework
- 100台以上の車両と歩行者がいるシーンでもLidar1つでdetectionを可能とした
- embedded GPU上で150 fpsで動作
- 拡張性が高いarchitectureで高速動作、非常に参考になる
background
- 3d 処理
- 3dのまま: 計算コスト大
- BEV: 情報量落ちすぎて小さいobjectのdetectionができない
- Related works
- BEV 3d detection: PIXOR
- Voxel base 3d detection: VoxcelNet, SECOND
- BEV LV fusion detecion: MV3D, AVOD
- 3D semantic segmentation: PointNet, STD
- “End-to-end multi-view fusion for 3d object detection in lidar point clouds"
- multi view関連
- 別branchが走っていてデバッグが複雑
- “In contrast, our approach uses explicit features and representations for perspective and topdown view, which makes the system easy to train and debug; our network performs multi-class object detection and is an order of magnitude faster”
- RangeBase semantic segmentation RangeNet++
Method

- multi-classなのでclassごとの学習は要らない
- 7 classes: cars, trucks, pedestrians, cyclists, road surface, sidewalks, and unknown
- “We experimented with more or fewer classes but found the best results were obtained with this choice”
Segmentation

- input: Lidar range image (3, 64, 2048)
- (点の有無、depth, intensity)?
- 点の有無についての言及がない?
- 図を見ると欠損値自体はある
- [[stdcv_00032_baidu_seg]] とか考えるとそうじゃない?
- output: 7 class semantic image (7, 64, 2048)
- drivable spaceも出力される
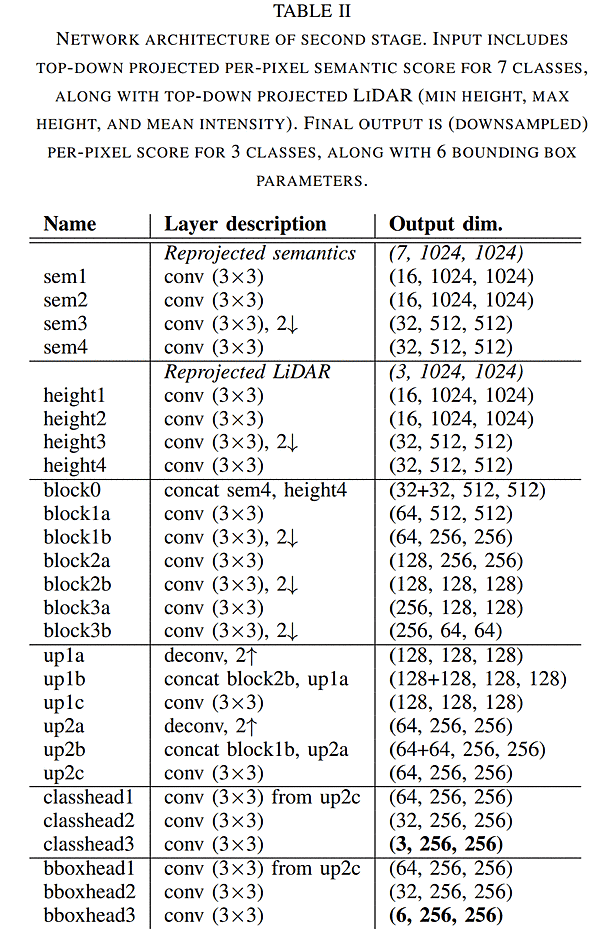
BEV detection
- input:
- BEV semantic image (7, 1024, 1024)
- BEV lidar feature (min height, max height, mean intensity) (3, 1024, 1024)
- network output
- classhead 3class (3, 256, 256)
- bboxhead3 (6, 256, 256)
- (δx, δy) 重心, (wo, lo) object size , (sin θ, cos θ) yaw
- final output
- class, (δx, δy) 重心, (wo, lo) object size , (sin θ, cos θ) yaw
Projection

- 以下考察
- BEV semantic image のinput: 生dataのlidar featureを入力する
- " Using class probabilities (rather than the most likely class) enables the network to perform
ore complex reasoning about the data (e.g., a person on a bicycle); we experimented with both and found this approach to yield better results"
-
- probabilities = scoreみたいな話だろうか
- 複数点入っていたらscoreの平均だろうか?
- probabilities = scoreみたいな話だろうか
-
処理予想
- Lidar range image (10, 64, 2048) 点の有無、depth, intensity, 7class scores
- for point
- (u, v)座標系 -> x, y, z計算
- BEV point_num += 1
- BEV semantic image にscore足す + intensity足す
- depthはmin?max? ave?
- max height, min heightの更新
- intensity / point_num, score / point_num
-
できあがっているもの
- BEV semantic image (7, 1024, 1024)
- BEV lidar feature (min height, max height, mean intensity) (3, 1024, 1024)
network
- Loss function
- focal loss for the classification head and L1 loss for the regression head
- Network
- それぞれのinputを feature map (32, 512, 512)にしてconcatしている
- その後classとbboxで別れる
clustering
- DBSCAN algorithm
- “M. Ester, H.-P. Kriegel, J. Sander, and X. Xu, “A density-based algorithm for discovering clusters in large spatial databases with noise,” in International Conference on Knowledge Discovery and Data Mining (KDD), 1996.”
- classのscoreでthreshold超えたものに対して行う
Experiment
- 3d detectionで何しているかを他の人にぱっと見せるのに非常にわかりやすい図
- こういう気配り的なものもいい論文だなと思う

- 2 stageは一気通貫でもtrainingできるが、データ・セットが対応していないので別々にtrainしている
- segmentation dataset: semantic kitti
- object detection dataset: kitti
- semantic KITTIとオレオレデータセットの両方で結果を示した
- param
- BEV size: 80m *80m
- cell size(1024): 7.8cm *7.8cm -> output(256) 31.3 cm
- TensorRTを使用
Discussion
- 非常に理にかなったframework
- range image + BEVなら2dで考えられるのでデバッグが非常にしやすい
- range image basedやBEV baseを
- 2-stageの中では拡張性が高いので使いやすいと思われる