summary
- sensor dropoutを用いて Detection + PredictionにおけるSensorのcontriobutionを解析
- from Uber

Model
- 2つの合体
- RV-MultiXNet (S. Fadadu, S. Pandey, D. Hegde, Y. Shi, F.-C. Chou, N. Djuric, and C. Vallespi-Gonzalez. Multi-view fusion of sensor data for improved perception and prediction in autonomous driving)にて検証
- M. Shah, Z. Huang, A. Laddha, M. Langford, B. Barber, S. Zhang, C. Vallespi-Gonzalez, and R. Urtasun.
Liranet: End-to-end trajectory prediction using spatio-temporal radar fusion. In CoRL, 2020.
- BEV branch
- 10 past sweeps of LiDAR points are voxelized onto a BEV grid
- fused with rasterized map channels
- radar features extracted by a spatio-temporal network as described in Liranet
- RV feature is projected onto BEV and fused with the BEV feature map
- Lidarの位置情報は必須なことに注意
Sensor Dropout
- Sensor Dropout (G.-H. Liu, A. Siravuru, S. Prabhakar, M. Veloso, and G. Kantor. Learning end-to-end multimodal sensor policies for autonomous navigation)では simulationのみだったのをreal dataに適応させた
- Sensor dropoutを用いてmodelのロバスト性を大きくした
Experiment
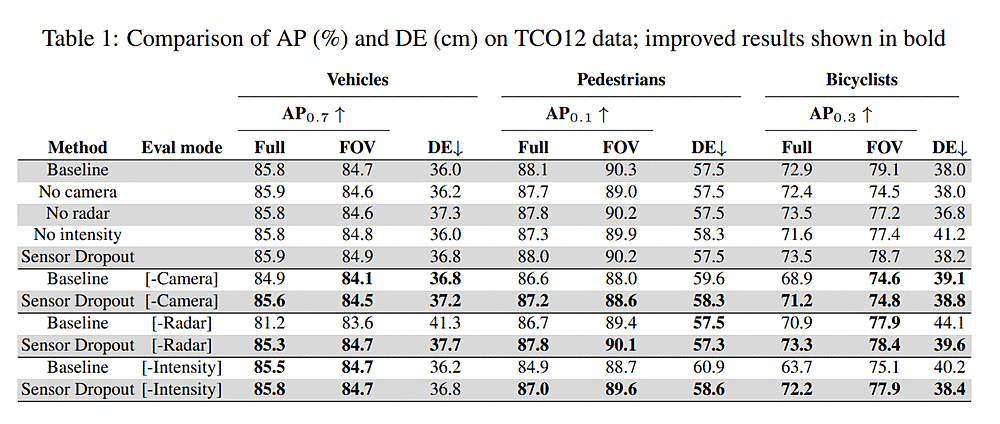
- Method(=恐らく学習時に何を使ったかのこと)、Eval modeに注意
- Camera無し学習、Camera無し評価: AP for pedestrians (-1.3%) and bicyclists (-4.6%) in the camera FOV
- Radar無し学習、Radar無し評価 the DE metric for vehicles regresses by 1.3cm, as radar helps provide velocity estimates on the vehicles
- LiDAR intensity無し学習、LiDAR intensity無し評価 shows 1.5% and 3.2cm regression in AP and DE for bicyclists, respectively
- Sensor無し評価
- Baseline(全載せ学習)vs Dropoutで学習したモデル
- dropout rate set to 0.2 for camera and radar and 0.1 for LiDAR intensity
- これはdropoutそれぞれで学習したモデルなのか、全てdropoutしたのか(前者な気がする)
- Sensor dropを用いて学習した奴だと、Sensorが実際にdropしてもちゃんと検知できる
- feature dropout vs input dropoutだと、featureの方が結果がよかった
- input 0に対するfeatureが変な値出している可能性がある = weight0にするべきかもしれない
Discussion
- 非常に筋が良い気がする
- ただリアルタイム性は微妙かも・・・?