summary
Dataset
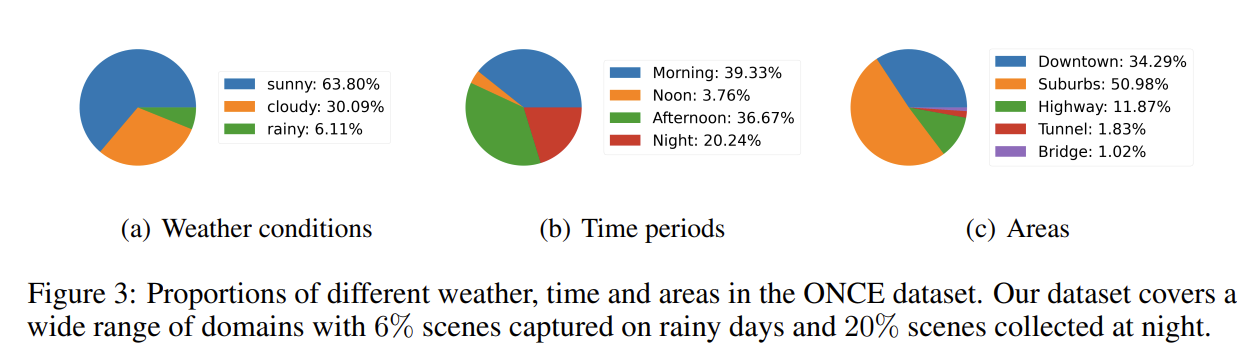
- ひたすらsceneが多い
- 半教師データセットらしい
- アノテーションはそんなに多くないのでテストデータとして良いかも知れない
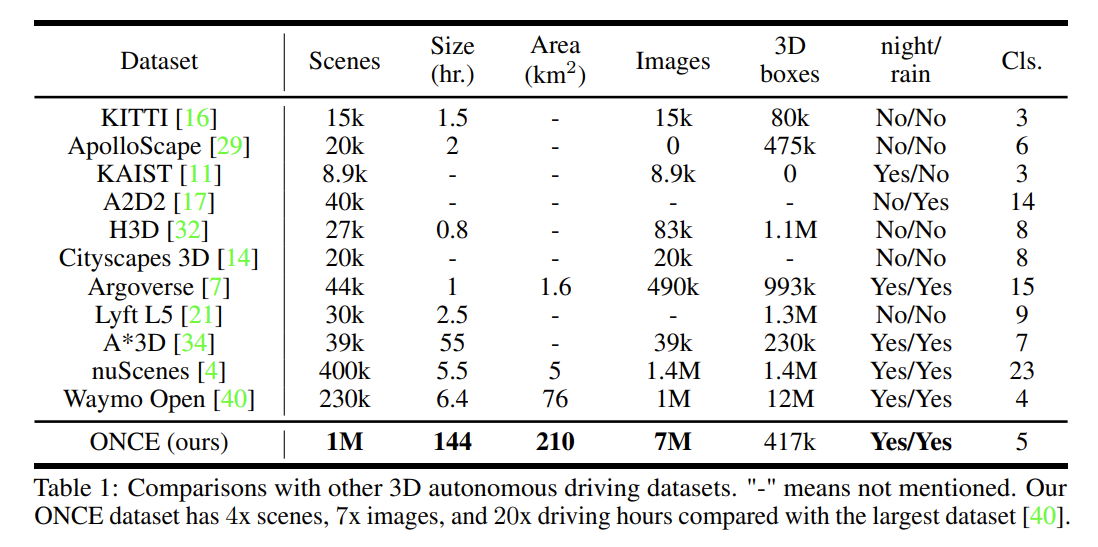

- Lidar * 1: 40-beam LiDAR (記載はないが、40だとHesaiか?)
- 10fps取得、dataは2fpsにdown sample
Evaluation
- orientation-aware
- $ AP ^ {Ori} _ {3D} = 100 \int _ 0 ^ 1 \max{ (p (r’ \vert r’ ≥ r)) } dr $
Benchmark

3D object detection model

- 全体としてはCenterPointsが強い
- なぜかPV-RCNNのvehicleが強すぎる
- PedestrianはCenterPoints圧勝
- Anchor assignments (SECNED) vs. center assignments (CenterPoint)
- centerbased method shows stronger localization ability which is required for detecting small objects, while the anchor-based method can estimate the size of objects more precisely
- Single-modality vs. multi-modality. PointPainting [43] appends the segmentation scores to the input point clouds of CenterPoints [52], but the performance drops from 61.24% to 59.78%.
- PointPaintingをやるにはSemantic segmentationも一緒に学習できるdatasetにしないと旨味が少ない
- “We find that the performance of PointPainting heavily relies on the accuracy of segmentation scores, and without explicit segmentation labels on the ONCE dataset, we cannot generate accurate semantic segmentation maps from images, which brings negative effects on 3D detection”
Self-Supervised Learning for 3D Object Detection
- SECOND base
- Self-Supervised Learning
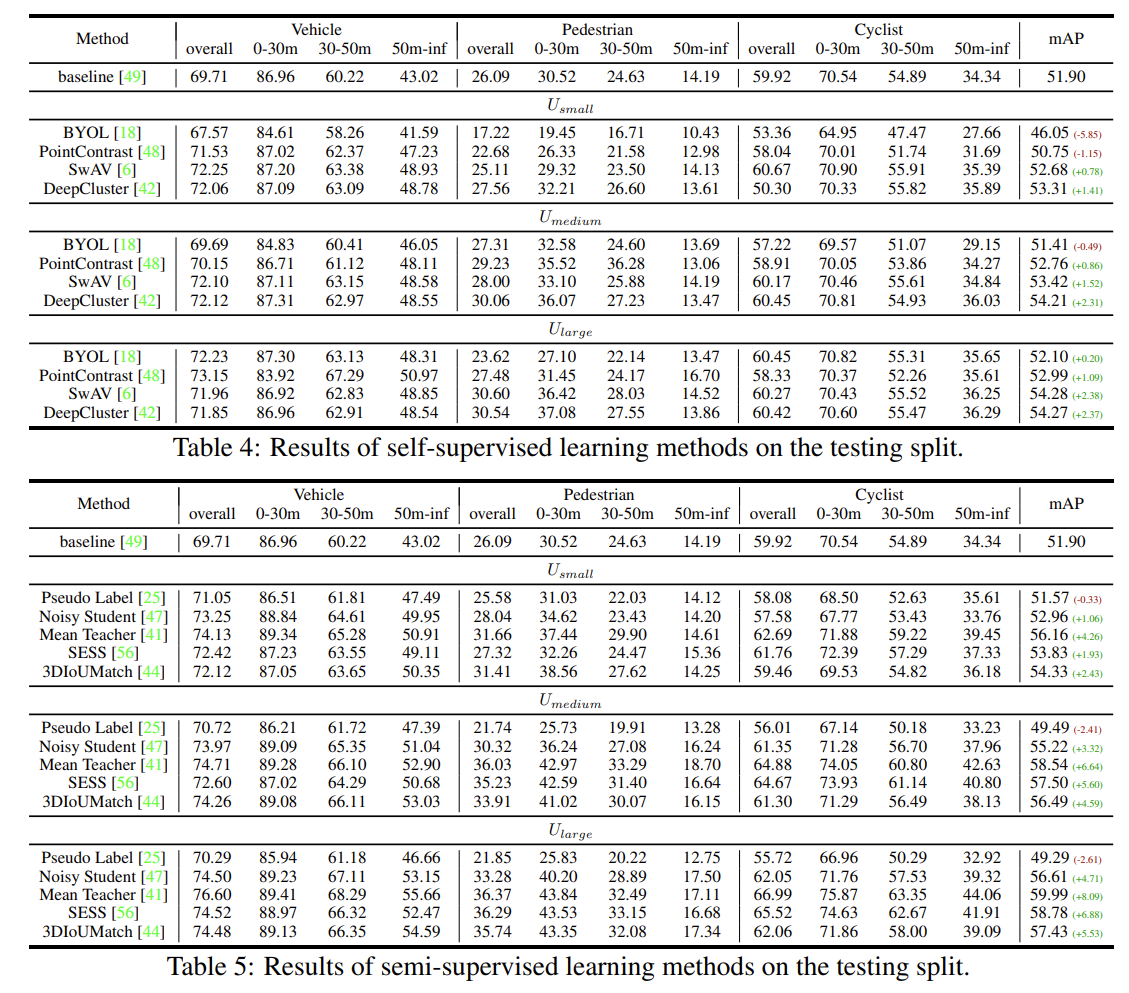
- Self-supervised learning on unlabeled data
- semi-supervised learning
- 正直CenterPointsレベルに全く達していない
- とはいえbaseline (51.9) + Mean Teacher で+4-8pt
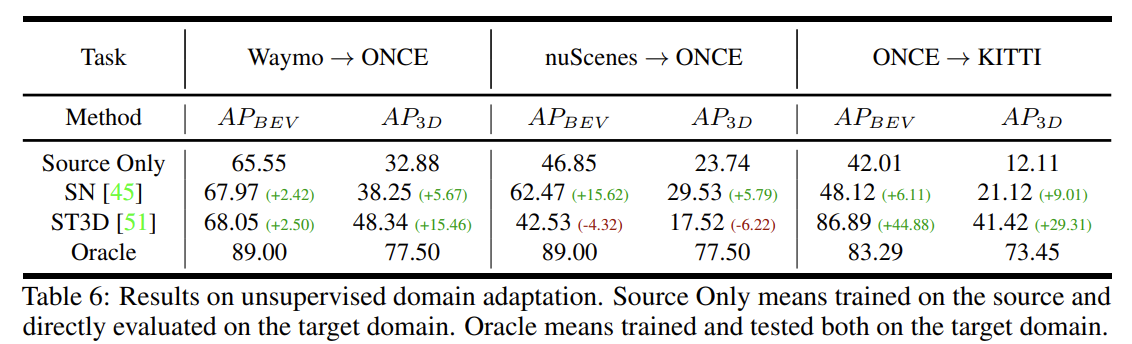
domain adaptation
- 逆にfine tuningしなかったらこんなもんなのか
Discussion
- For future works, we plan to support more tasks on autonomous driving, including 2D object detection, 3D semantic segmentation and planning.