概要
- 流れ
- PointNet -> PointNet++
- TangentConv
- SPLATNet: high-dimensional sparse lattice: not scale
- SuperPoint Graph
- Online Lidar
- SqueezeSeg and SqueezeSegV2
- spherical projection, a conditional random field (CRF)
- limit: 90deg, CRFをlabelの探索をすべての点群に対して行うものに変更
手法
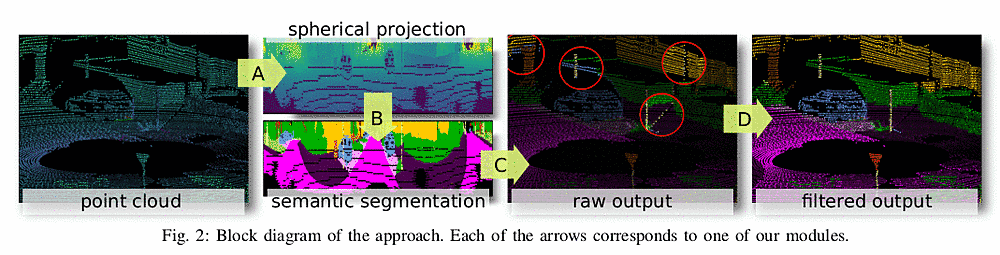
III.A . range image化
- 点群 ($p_i$ = (x,y,z)) (3D) -> 球面投影されたデータ (u v) ( = puesudo range image, 2D)
- 列: 同時刻 行; 異なる時間のずれは自動車レベルの速度なら無視できる仮定 -> ほんと?
- vehicle motion
- $$ \begin{pmatrix} u \\v \end{pmatrix} = \begin{pmatrix} \frac{1}{2} (1-\arctan (y, x) \pi^{-1} w \\ {1-(\arcsin (z r^{-1})+f_{u p}) f^{-1}) h} \end{pmatrix} $$
- Tensor (5 × h × w) r, x, y, z, and remission
- (u, v)
III.B . 2D CNN semantic segmentation
- 球面投影されたデータ -> Semantic segmantation (2D)
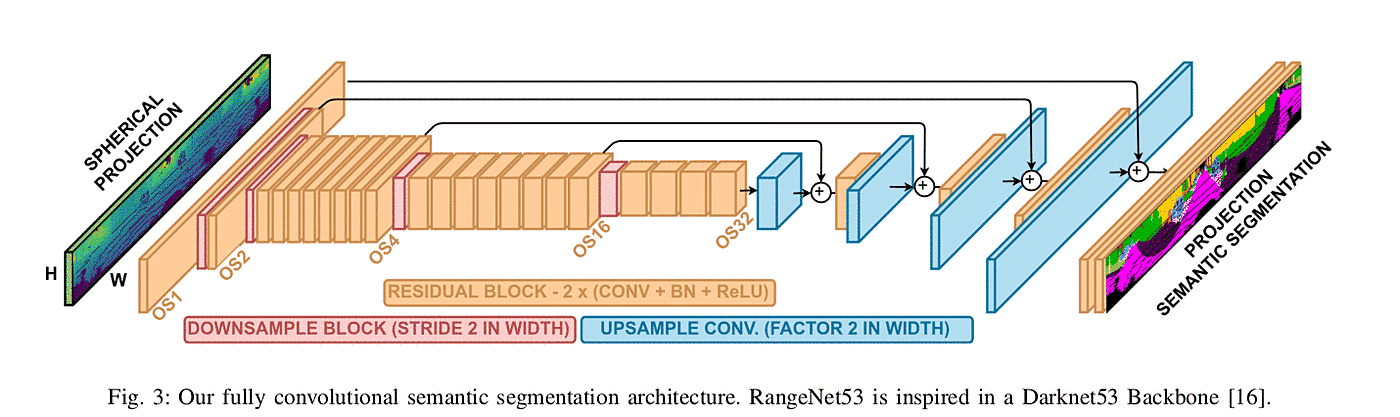
- SqueezeSeg base: encoder-decoder hour-glass-shaped architecture
- downsampling is 32
- Loss function: $$\mathcal{L}=-\sum_{c=1}^{C} w_{c} y_{c} \log (\hat{y}_{c}), \text { where } w_{c}=\frac{1}{\log (f_{c}+\epsilon) }$$
- fc: inverse of its frequency, よく出てくるラベルの影響力を下げる
- アーキテクチャの流れ Darknet53 (Yolov3) -> RangeNet53 -> Rangenet++
- data size
- velodyne 64列を使っているのでh = 64
- w = 2048 - 512で評価
III.C. 2Dto3D semantic transfer
- Semantic segmantation (2D) -> rawoutput (3D)
- (u, v)と各点群のペアの情報を用いる
- 最後の層見ると特徴量n層?
III.D. 3Dpost-processing
rawoutput (3D) -> filtered output (3D)
- rawoutput (3D) + rangeImage (2D) -> filtered output (3D)
- そのままのoutputだとshadow-like artifactsが出現する
- range image based 3Dpost-processing to clean the point cloud from undesired discretization and inference artifacts, using a fast, GPU-based kNN-search operating on all points.
- Efficient Projective Nearest Neighbor Search for Point Labels
- k-Nearest-Neighbor (kNN) base, 速い
- 閾値を追加する cut-off閾値 近い点群とする最大距離
- 並列化可能で速い
- Data
- Range Image $I_{range}$ of size W × H,
- Label Image $I_{label}$ of predictions of size W × H,
- Ranges R for each point p ∈ P of size N ,
- Image coordinates (u, v) of each point in R.
- Result: Labels L consensus for each point of size N .
- algorithm
- Get S^2 neighbors N'
- Get neighbors N
- Fill in real point ranges
- Label neighbors L 0 for each pixel
- Get label neighbors L for each point
- Distances to neighbors D for each point
- Compute inverse Gaussian Kernel
- Weight neighbors with inverse Gaussian kernel
- Find k-nearest neighbors S for each point
- Gather votes.
- Accumulate votes.
- Find maximum consensus.
- ハイパラ
- (i) S which the size of the search window
- (ii) k which is number of nearest neighbors
- (iii) cut-off which is the maximum allowed range difference for the k
- (iv) σ for the inverse gaussian.
- 4パラ総当りは結構しんどそう
- III.Cまでのハイパラにも依存していそう(特に解像度)

実験
- SemanticKITTI http://semantic-kitti.org/
- SuMa++ (Semantic SLAM)と合わせてslam+localization
- dynamic objectにたいして取り除くような処理
- 64*2048 12fps
- border-IoU: how far a point is to the self occlusion of the sensor
考察
- 全体として読みやすい
- range image base
- 実機応用する時、センサ依存が気になる
- そもそもSemantic segmantationをしているけどdetectionに比べるとやっていることがリッチ過ぎる?
- personのdetectionにはゆーてセマセグくらい必要?
- 実験として
- 1つのデータセットのみでの評価
次読むやつ
- J. Behley, C. Stachnis. Efficient Surfel-Based SLAM using 3D Laser Range Data in Urban Environments, Proc. of Robotics: Science and Systems (RSS), 2018.