概要

intro
- 1 (range image) was proposed
- SqueezeNet
- PointSeg
- RIU-Net: Embarrassingly simple semantic segmentation of 3D LiDAR point cloud.
- 3D point cloud to U-net自体の先行研究はある
- rangeimage baseは精度が悪いが、自分たちは良くしたというのが主張
手法
3.2 Range Image
- input : 3D lidar point cloud
- output 2D range image (H *W)
- rangeimage
- 欠損値 0 for empty pixels or 1
- 5 channels: x, y, z(3D pos), r(reflectance). d (spherical depth)
- n H × W = Card(P)
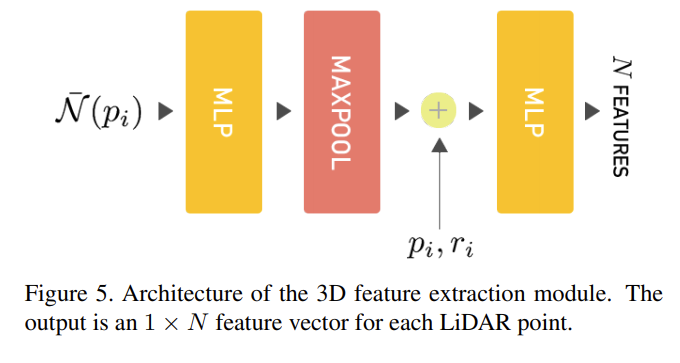
- input 3D point cloud, 2D range image
- output N channel 3D features for each pi
- shape: Card(P) × N matrix -(reshape)-> = H × W × N range-image
- 8-connected neighborhood N(p)
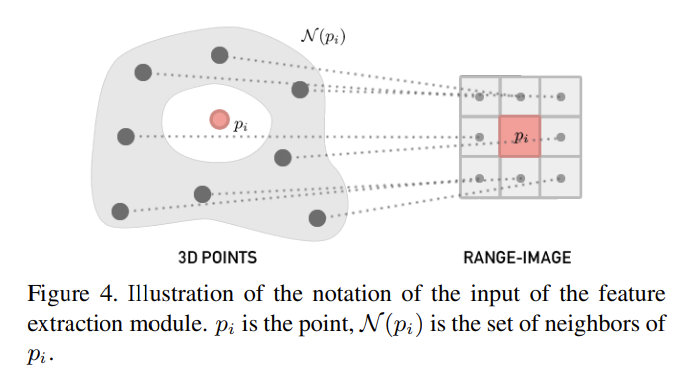
- N meaningful high-level 3D features for each point and to output a range-image with N channels
- 特徴量抽出
3.4. Semantic segmentation
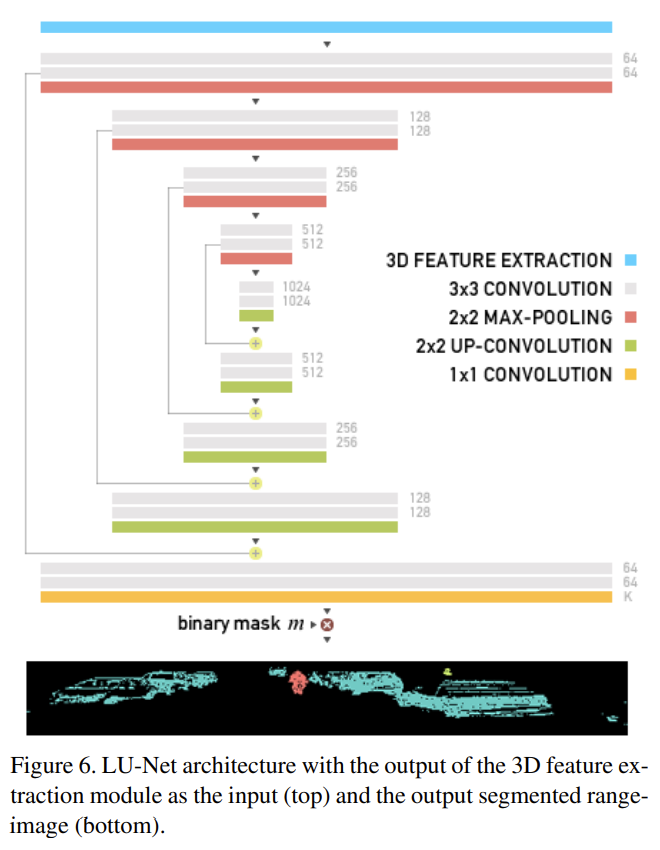
- m: 0 1で点があるかないか
- Loss function: Focal loss for dense object detection
- 小さいobjectや少ないラベル(人等)に係数大きめ
- γ = 2 is the focusing paramete
実験
- N = 3
- 24fps = 40ms
- 小さい人の情報を落とすことがある

- 比較
- Nを用いると$\bar{N}$に比べて劣化する
- 恐らく絶対座標そのものより近隣のと関係の方が特徴量をつかむのに適しているから
- データセットの欠落
- In Figure 9e), a car in the foreground is missing from the groundtruth, this causes the IoU to drop from 89.7% when ignoring this region of the image, down to 36.4%. Thus, removing examples with wrong or missing annotations in the dataset could lead to better results on LU-Net as well as on other methods. However, due to the amount of examples in the dataset, having a perfect annotation is practically very difficult
議論