Simple-BEV: What Really Matters for Multi-Sensor BEV Perception? (arxiv 2022/09)
Summary
- https://simple-bev.github.io/
- https://github.com/aharley/simple_bev
- NuScenes, Lyft でtrain code
- NuScenesはpretrain modelあり
- Camera-Radar fusion の BEV detection 検出
- input: Camera * 6 (360度) + radar pointcloud
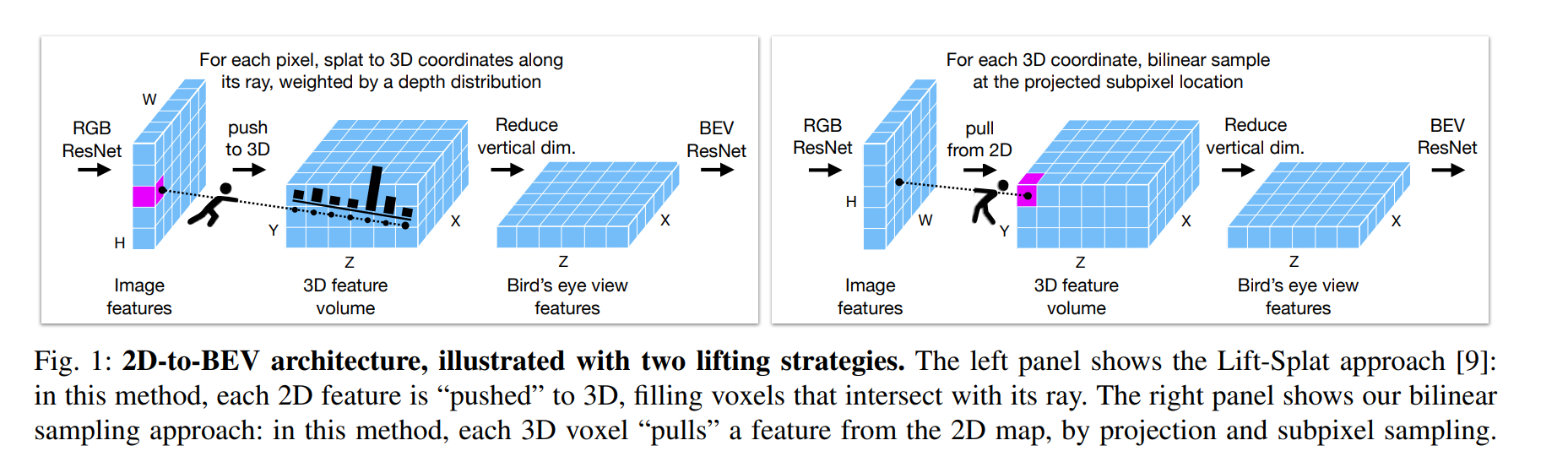
- Depth-based, Homography-based ではない
- 地図使わないのでdrivable areaの推定などは行っていない
- 下図の地図は可視化に使っているだけで出力としては青色のところのみ
- 論文での評価はvehicleのdetectionのみ
- bicycleなどは含んでいるがpedestrianが含まれていない

- Camera-only BEV detection でも、Camera-radar BEV detectionでも動作するアーキテクチャ
- 基本的にはBEVFusionの考え方で、CenterPointへのインテグはしやすい
- 大体A100 (恐らくpythonで) 80ms、性能と推論速度のバランスは良さそう
- Backboneを軽くして、tensorRT使って並列化すれば許されるラインに収まると思う
Method
- Grid
- 200 * 200 * 高さ8 の解像度
- 距離 100m四方 (metricとしては 高さ10m)
- voxel lengths: 0.5m × 0.5m 高さ× 1.25m
- 概要
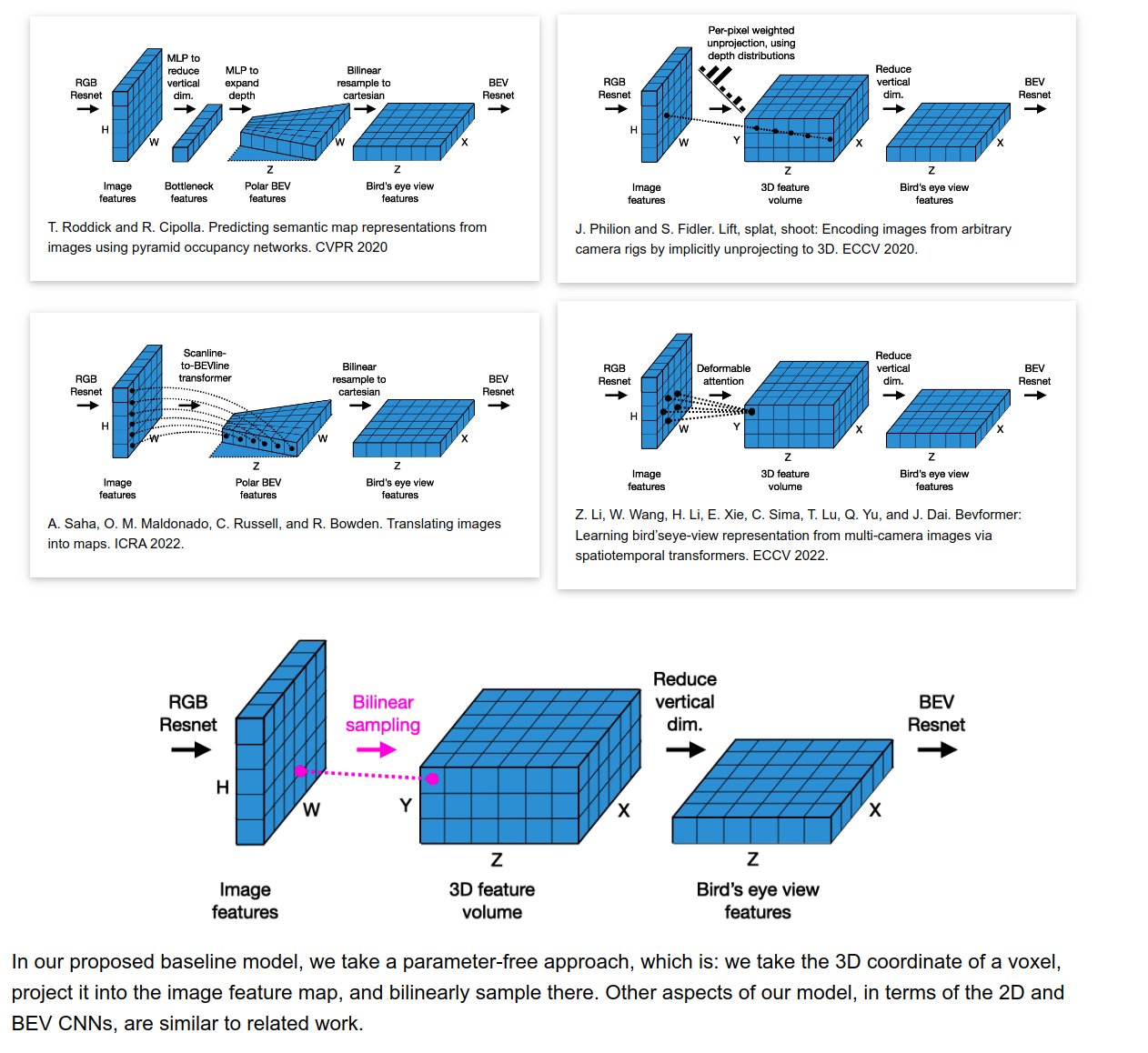
- 6つのCameraに対して 2D ResNet で特徴量を得る
- 3D projection + reduce to a BEV plane
- BEV ResNet
- Lifting strategy: 3D projection + reduce to a BEV plane
- C × H/8 × W/8 -> C ×Z ×Y ×X -> (C · Y) × Z × X,
- 1つのvoxelに $C$のarrayが入っていると解釈するのが良さそう
- 2D to 3Dでsamplingするのではなく、3D側から2Dを参照する
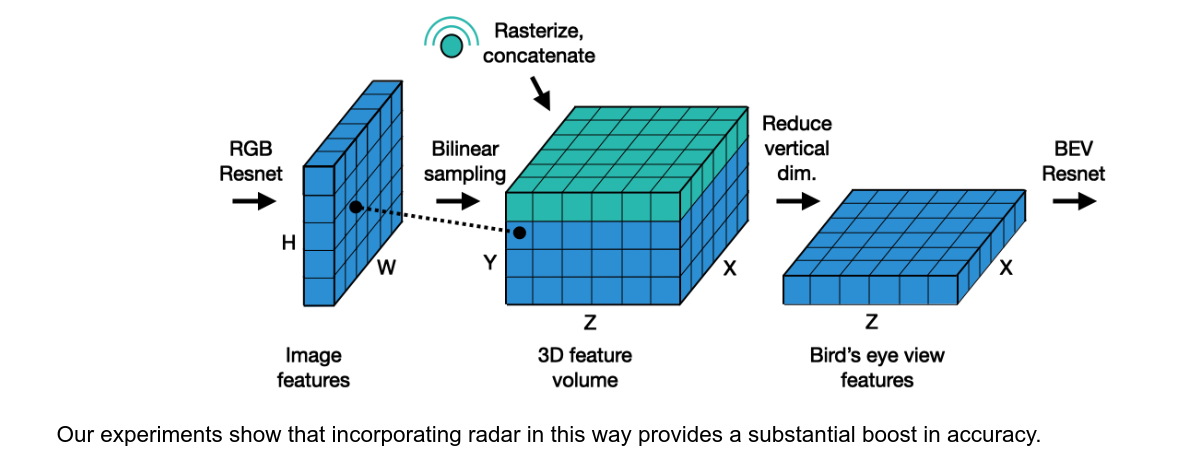
- radar有りのとき
- R×Z×X で3Dの層に追加
- total of 18 fields, x, y, doppler + R = 15
- “consists of a total of 18 fields, with 5 of them being position and velocity” は多分間違えてる
- LiDAR有りの時
- Voxelize Y ×Z ×X, and use it in place of radar features
- Fusion BEV化
- 3×3 convolution kernel でconcat する
- (C · Y + R) × Z × X → C ×Z ×X
- ResNet-18 + segmentation task head (FIERY)
Experiment
- Dataset: nuScenes
- Label
- “vehicle”: bicycle, bus, car, construction vehicle, emergency vehicle, motorcycle, trailer, and truck
- training
- our model converges in 1-3 days
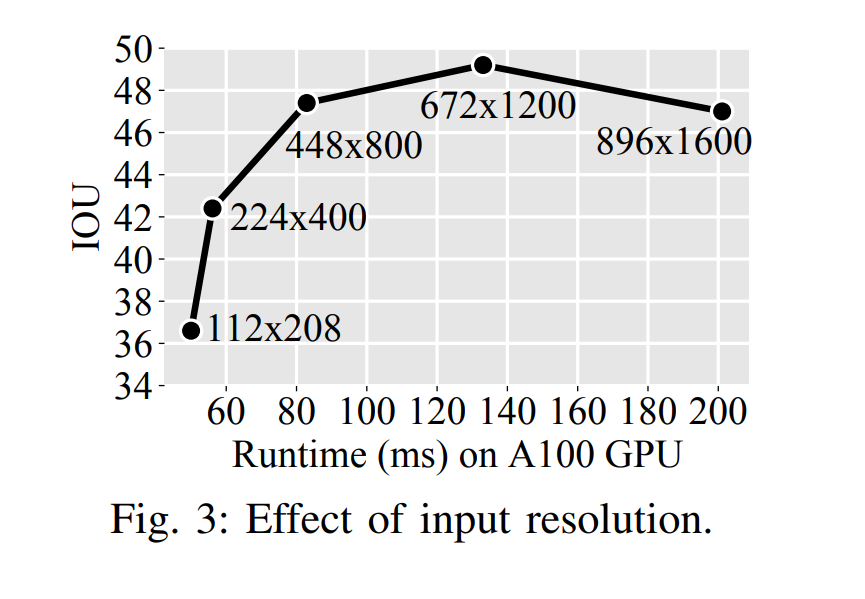
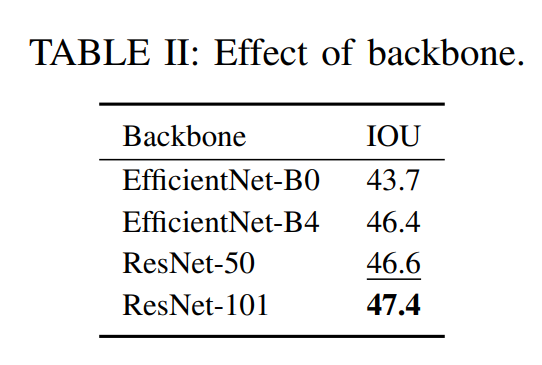
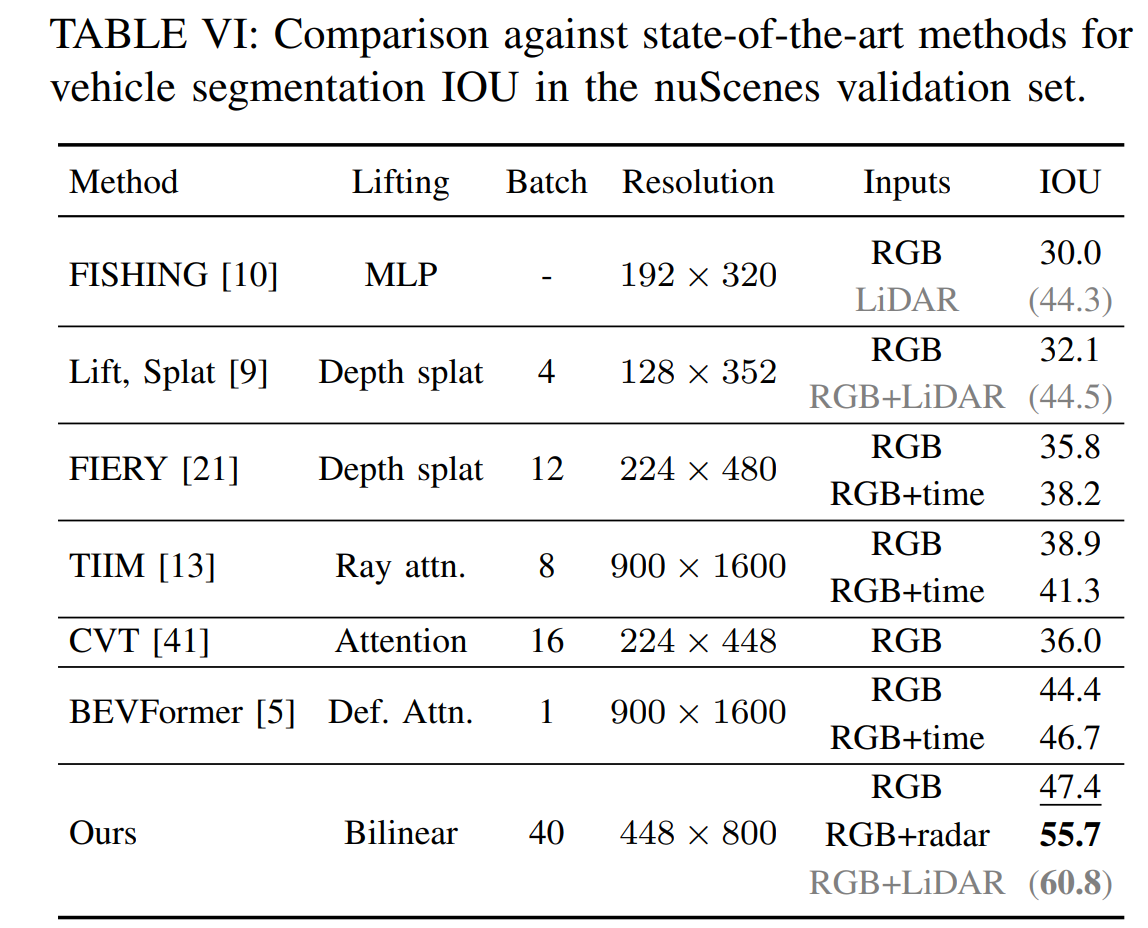
- 448 × 800 model: 47.4 IOU, 83 ms, 42M parameters
- BEVFormerより性能は低いが、推論速度は早い
- 37MはResNet-101から来ているので最近の軽いNetwork使えばもう少し削れるはず
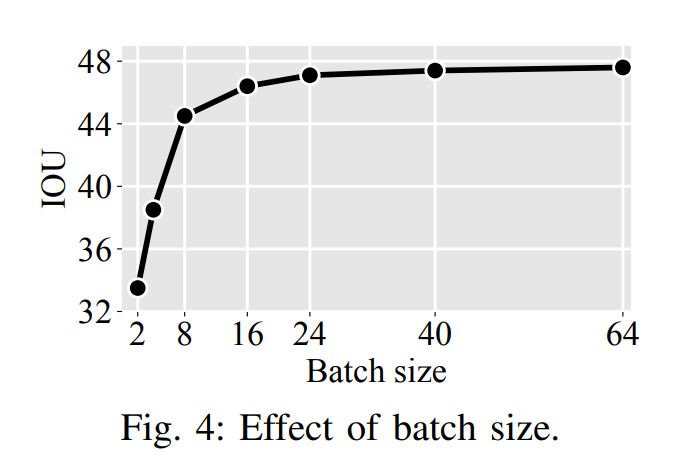
- augmentationは微妙
- Effect of augmentations, Effect of camera randomization, Effect of camera dropout
- LiDAR無しでも十分な性能出ている
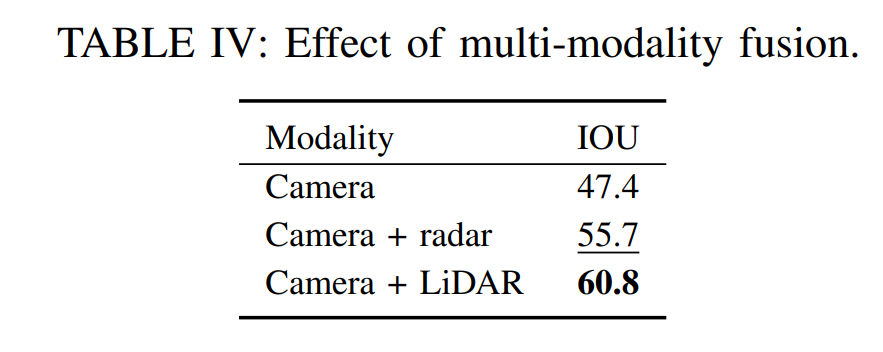
- Radar比較
- noise除去はやったほうが良いっぽい
- multiple sweepがしたほうが良いっぽい

- 動画
- Camera-Radarでそこそこできているように見える
- 多分mapは重畳させているだけで、出力としては青色のやつだけ
- 人の検出はしていない
Discussion