Find n’ Propagate: Open-Vocabulary 3D Object Detection in Urban Environments (arxiv 2024/03, ECCV2024)
Summary
- Open-Vocabulary 3D Object Detection
- https://github.com/djamahl99/findnpropagate
- contribute
-
- 2D VLM を用いたfrustum base手法
-
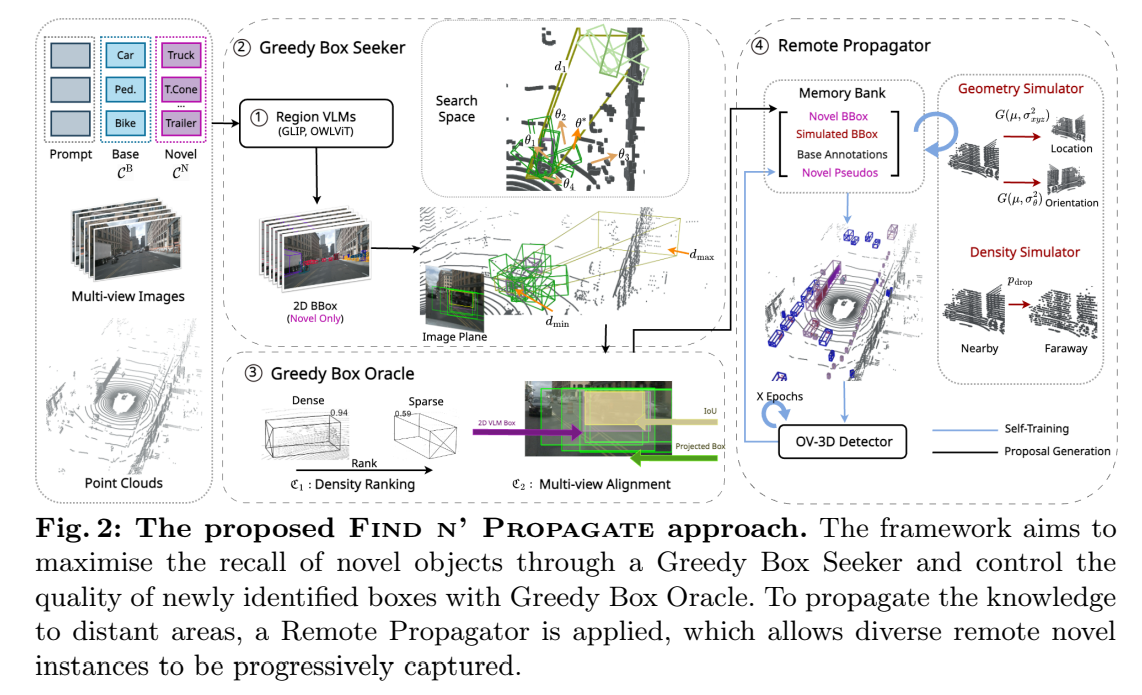
- Greedy Box Seeker
- frustumからsegmentしてspaceをsearchする
-
- Greedy Box Oracle
- multi-view alignment and density ranking で修正する機構
-
- Remote Propagator
- 遠距離にある novel pseudo label -> sparseになる
- memory に入れて活用する
-
Background
- 2D Open-vocabulary learning
- (1) distilling knowledge from large vision-language models (VLMs) such as CLIP [29] for feature map matching [9], region prompting [36, 42], bipartite matching [20]
- (2) employing pseudo-labelled boxes [49,50] or auxiliary grounding data [15, 23, 24, 46] as weak supervision in self-training
- 3D
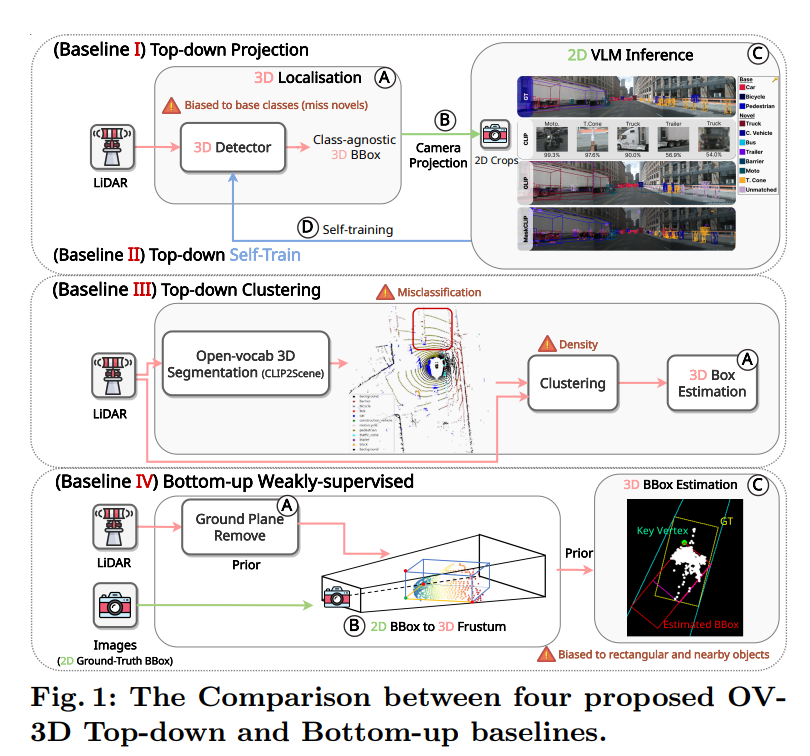
- (1) Top-down Projection
- (2) Top-down Self-train
- (3) Top down Clustering
- (4) Bottom-up Weakly-supervised 3D detection
- Bottom up について
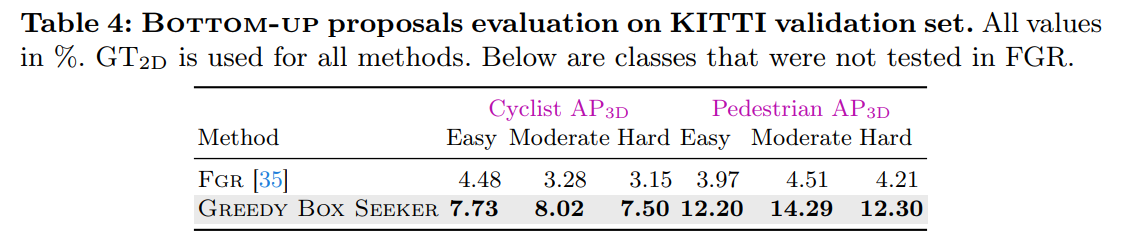
The Bottom-up approach presents a cost-effective alternative akin to weakly supervised 3D object detection, lifting 2D annotations to construct 3D bounding boxes. Different from Top-down counterparts, this approach is training-free and does not rely on any base annotations, potentially making it more generalisable and capable of finding objects with diverse shapes and densities. In Baseline IV, we study FGR [35] as an exemplar of Bottom-up Weakly-supervised and evaluate its effectiveness in generating novel proposals. FGR starts with removing background points such as the ground plane, then incorporates the human prior into key-vertex localization to refine box regression. However, their study was limited to regressing car objects, as their vertex localization assumes rectangular objects which do not hold for other classes
Method
-
- 2D VLM を用いたfrustum base手法
- region VLMs (GLIP) or off-the-shelf OV-2D detectors (OWL-ViT)
- k; proposalする的なイメージ
-
- Greedy Box Seeker
- frustumからsegmentしてspaceをsearchする
-
- Greedy Box Oracle
- Density ranlking
- distinguishing between the foreground and background is crucial
- multi-view alignment
- bboxを適当いい感じに広げる
-
- Remote Propagator
- geometry 位置角度をsimulateで変更する
Experiment
- Baseline
- TOP-DOWN Clustering: DBScanなど + CLIP2Scene
- Bottom up wealky supervised: FGR
- 結果
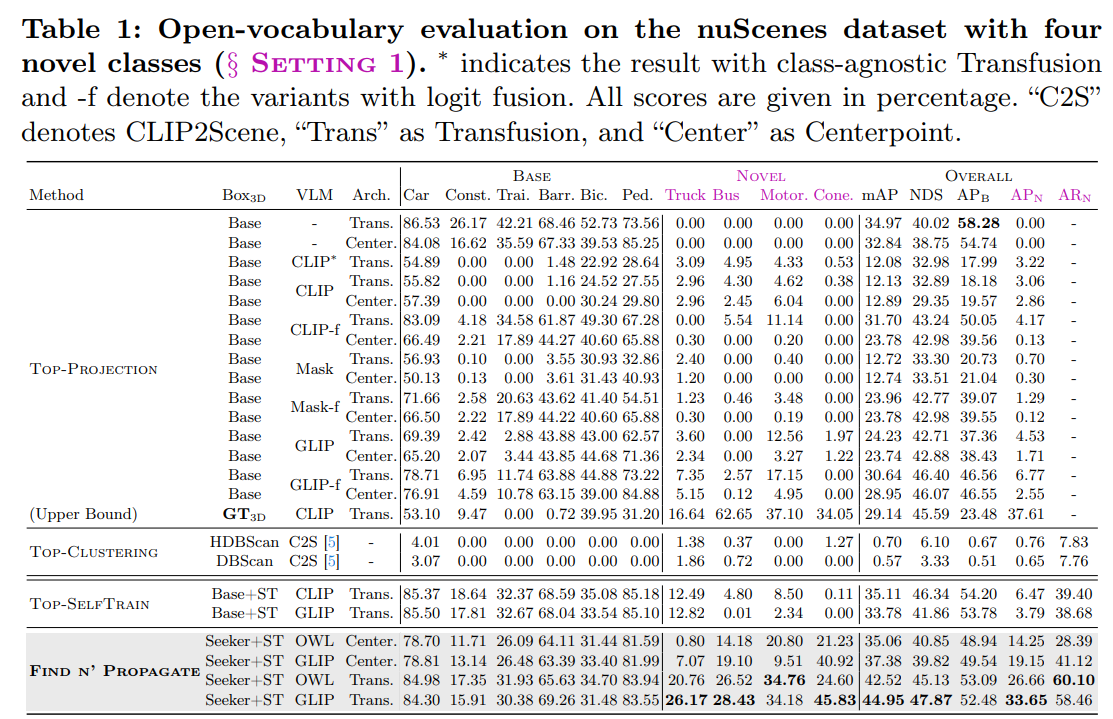
- 全部新しいclass
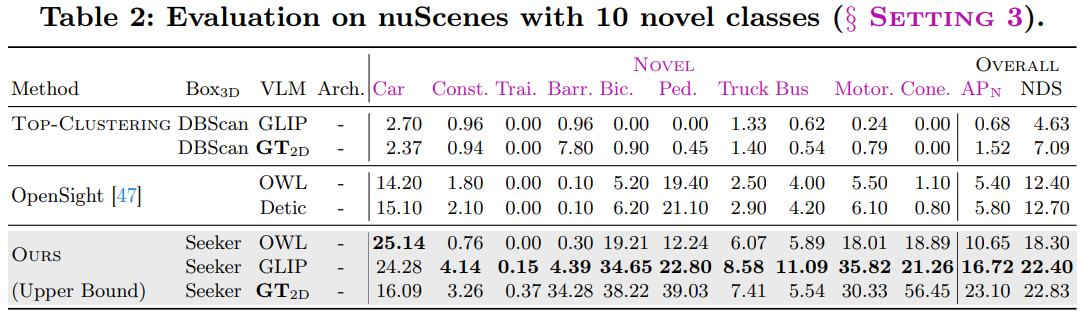
- 3 class -> 3 + 7 class
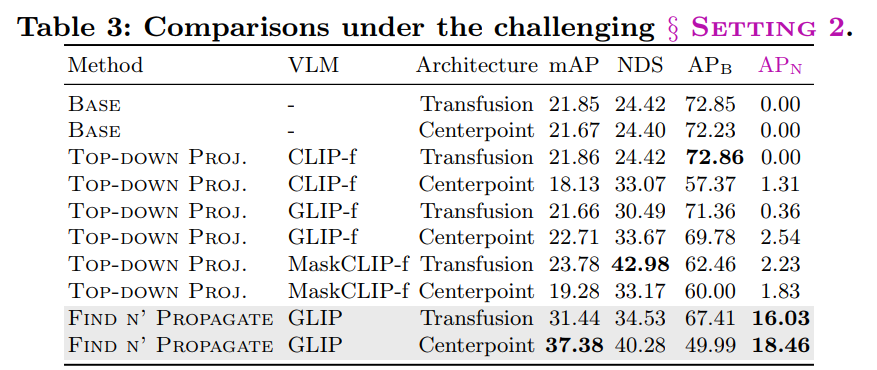
- Greedy box seeker の比較
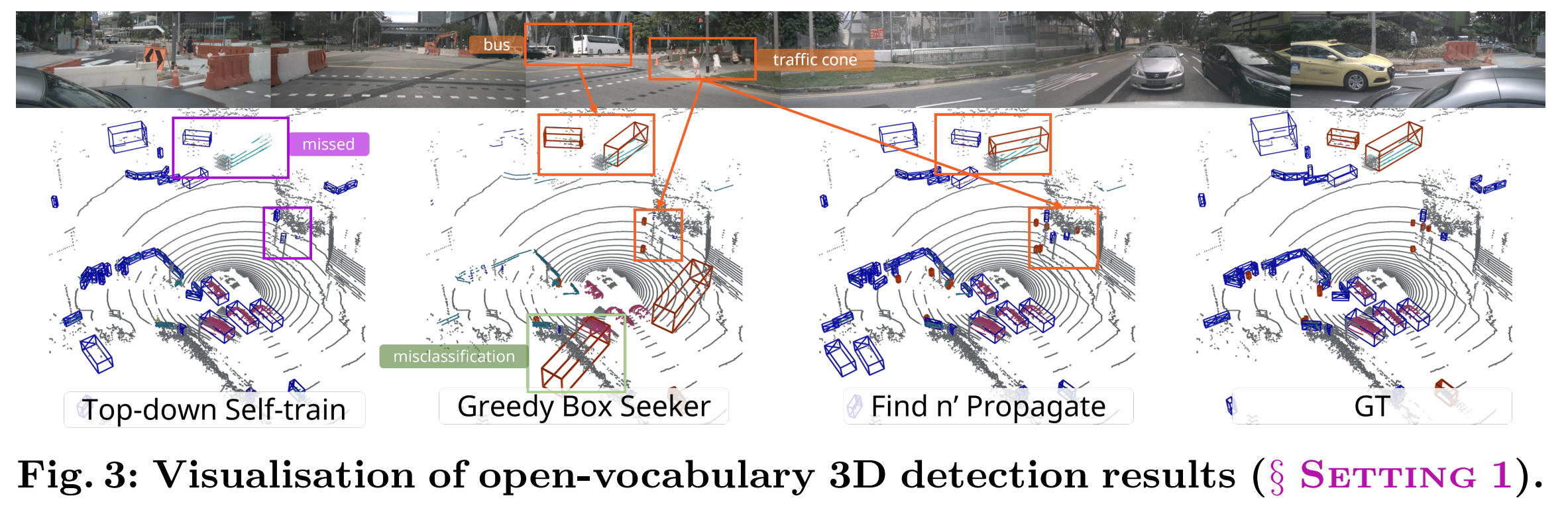
- 可視化
- 比較
- 回転と点群sparseのaugmentationが効いている
- Greedy box oracle はちょっとだけ効いている