MixSup: Mixed-grained Supervision for Label-efficient LiDAR-based 3D Object Detection (ICLR2024)
Summary
- MixSupを使ったsemantic point clustersの利用 + PointSAM(3D Panoptic segmentation)使ったpseudo label によるFew data 3D detection
- https://github.com/BraveGroup/PointSAM-for-MixSup
- contribution
- semantic point clusters as coarse labels の3D detectionへの活用
- PointSAMを使った semantic point clusters の作成
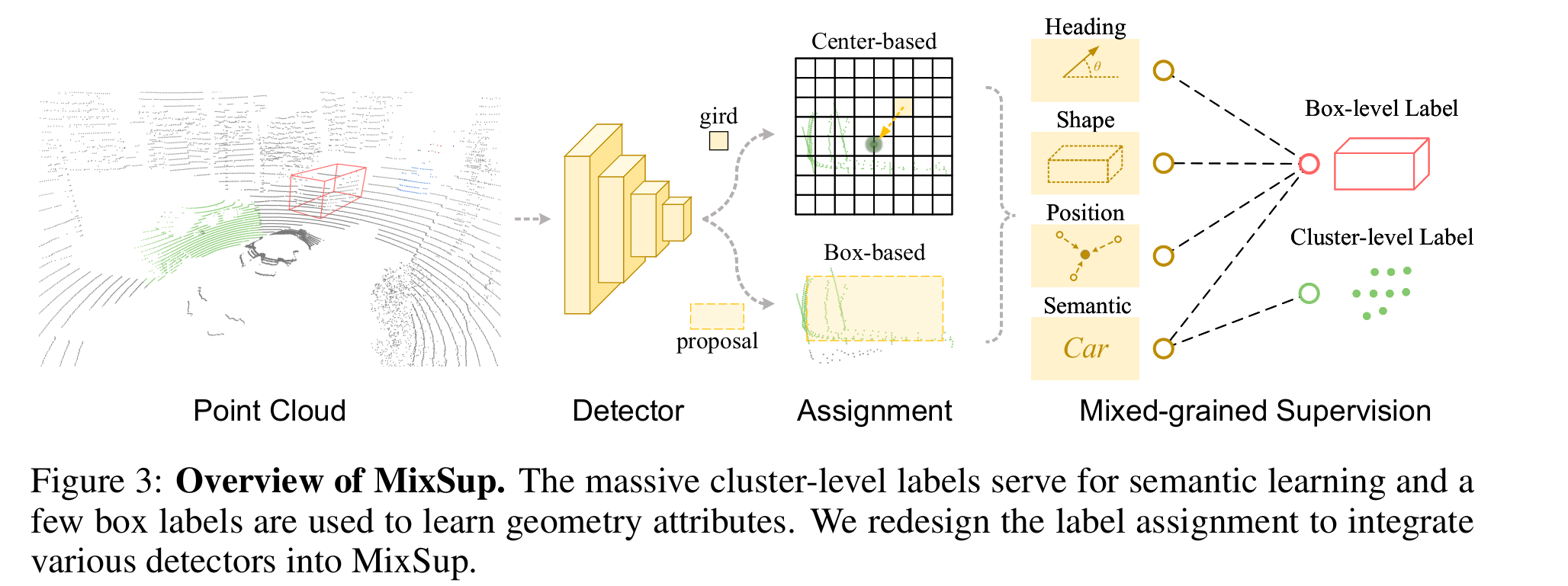
Method
- Architecture
- Cluster label のsupervisionを備えている
Data amount
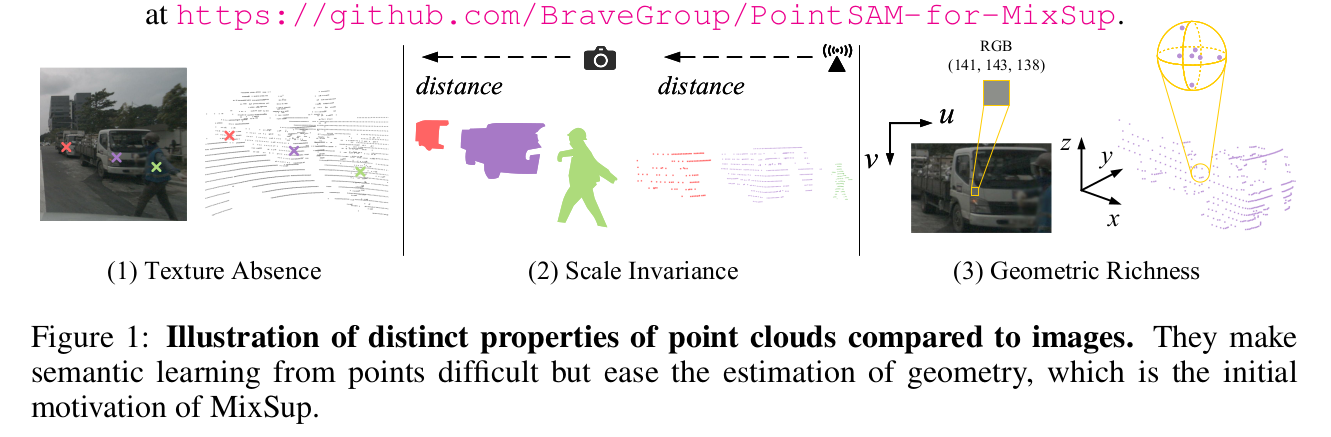
- Pointcloudの課題
- (1) Texture absence: 3D point cloud lacks distinctive textures and appearances.
- (2) Scale invariance: point clouds in the 3D physical world are scale-invariant to the distance from sensors since there is no perspective projection like 2D imaging.
- (3) Geometric richness: consisting of raw Euclidean coordinates, the 3D point cloud naturally contains rich geometric information.
- 思想
- A good detector needs massive semantic labels
for difficult semantic learning but only a few accurate labels for geometry estimation.
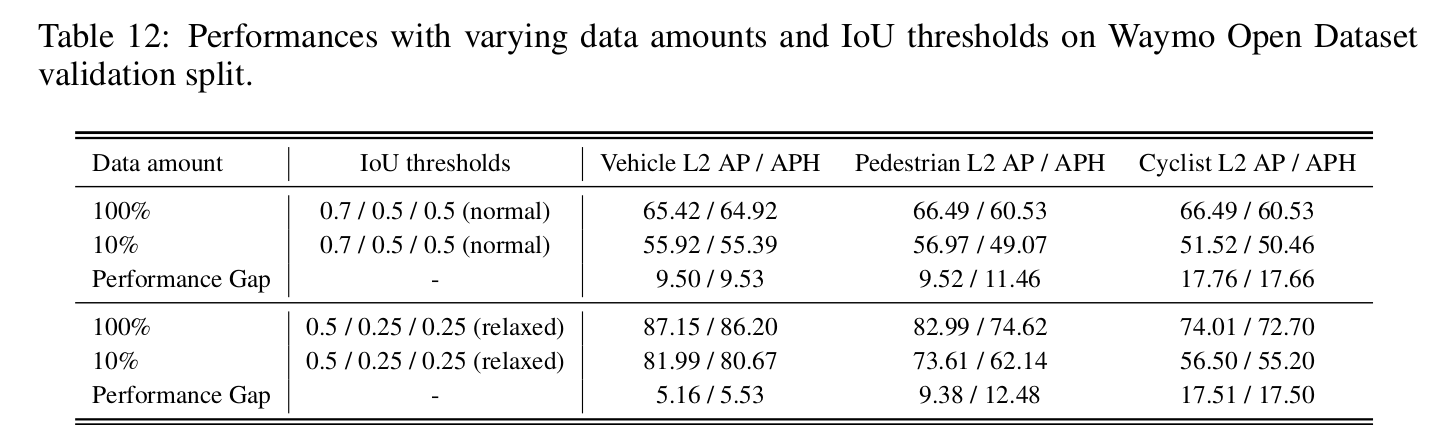
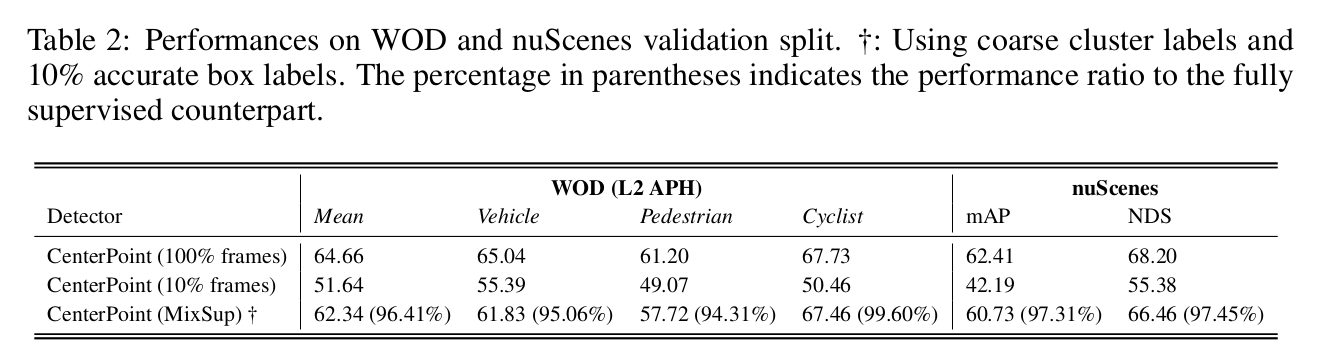
- data量に比べての性能
- 5%でそこそこの性能が出ている
- cyclistが厳し目
- “LiDAR-based detectors indeed only need a very limited number of accurate labels for geometry estimation. Massive data is only necessary for semantic learning”.

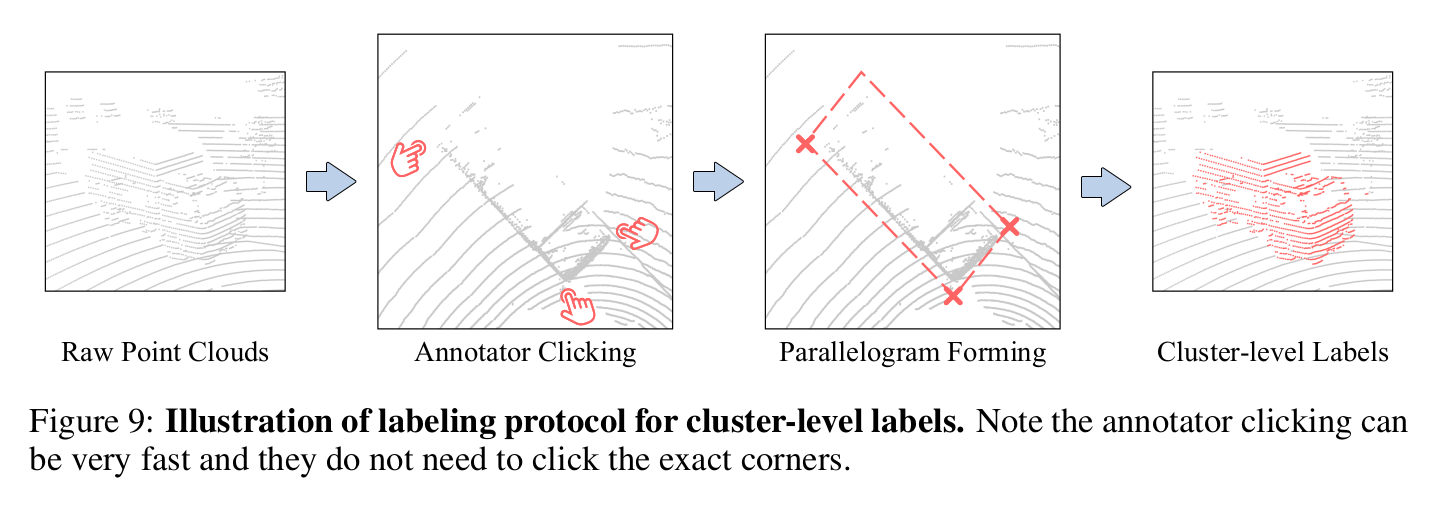
Coarse label
- Coarse label
- Appendix
- 3D box-level labels -> “coarse 3D cluster labels”
- (最終的にannotationに向きなどは存在しない状態になる + semantic labelは後付?)
- “The average time cost of a coarse cluster label is only 14% of an accurate box label”
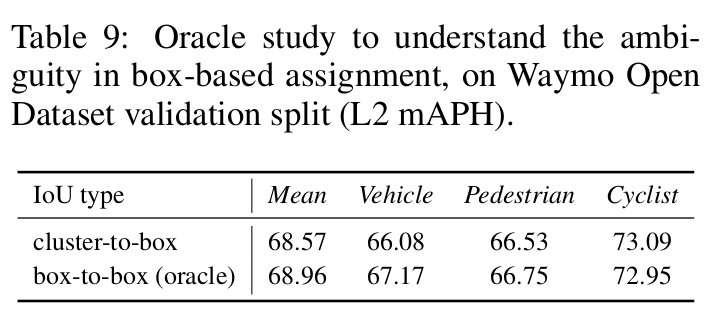
- Box based assignment
- Box cluster IoU -> Pointcloud IoU

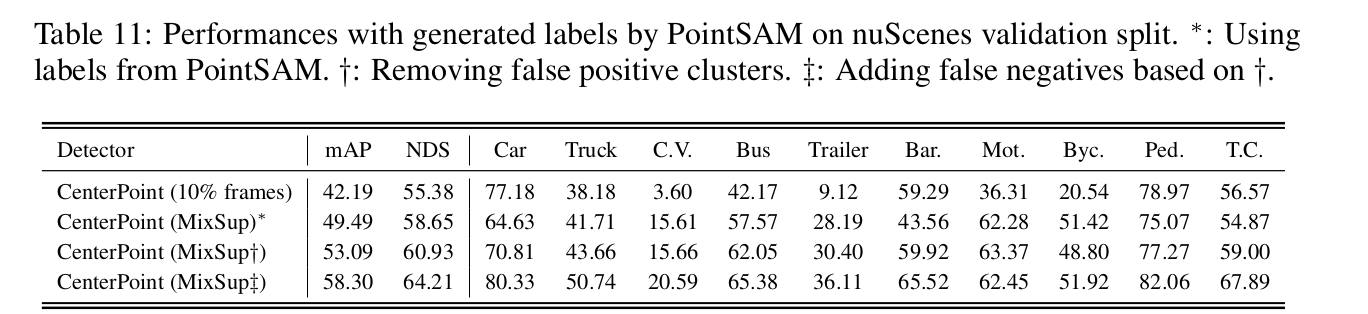
PointSAM
- PointSAM: 2D Sem seg -> prompt使って SAM で抽出 + PointPainting -> 3D Instance Segmentation
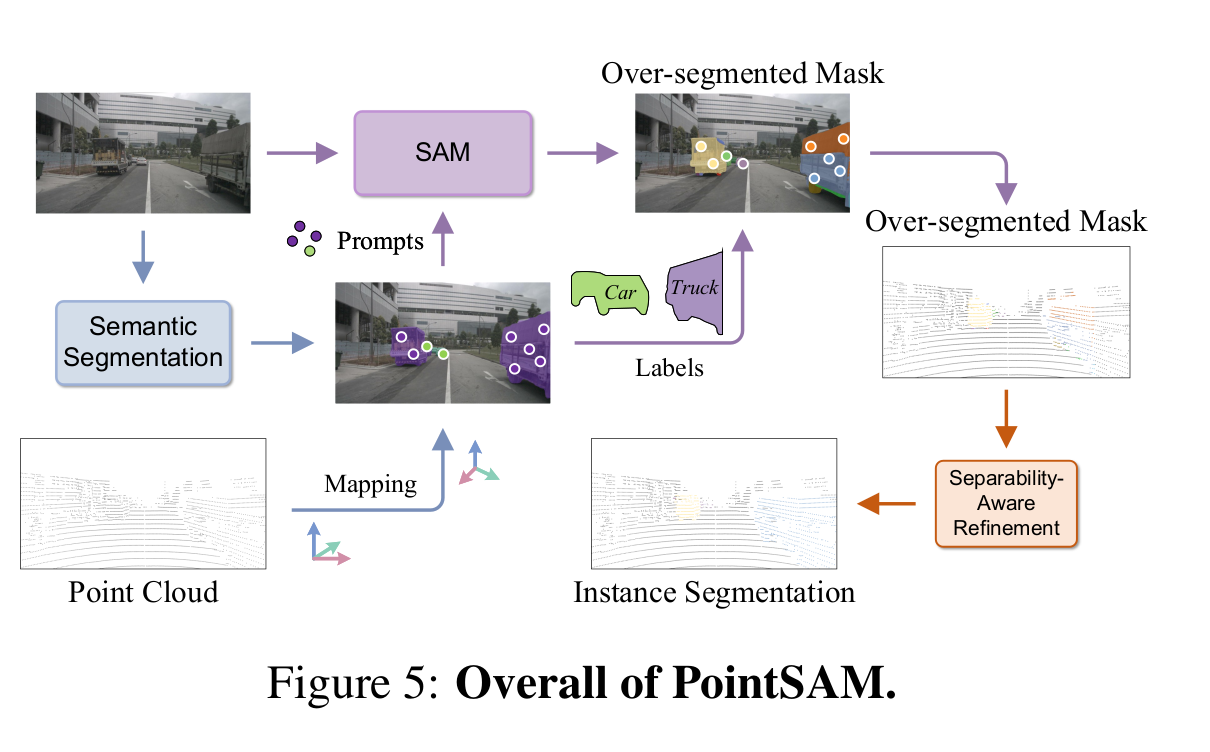

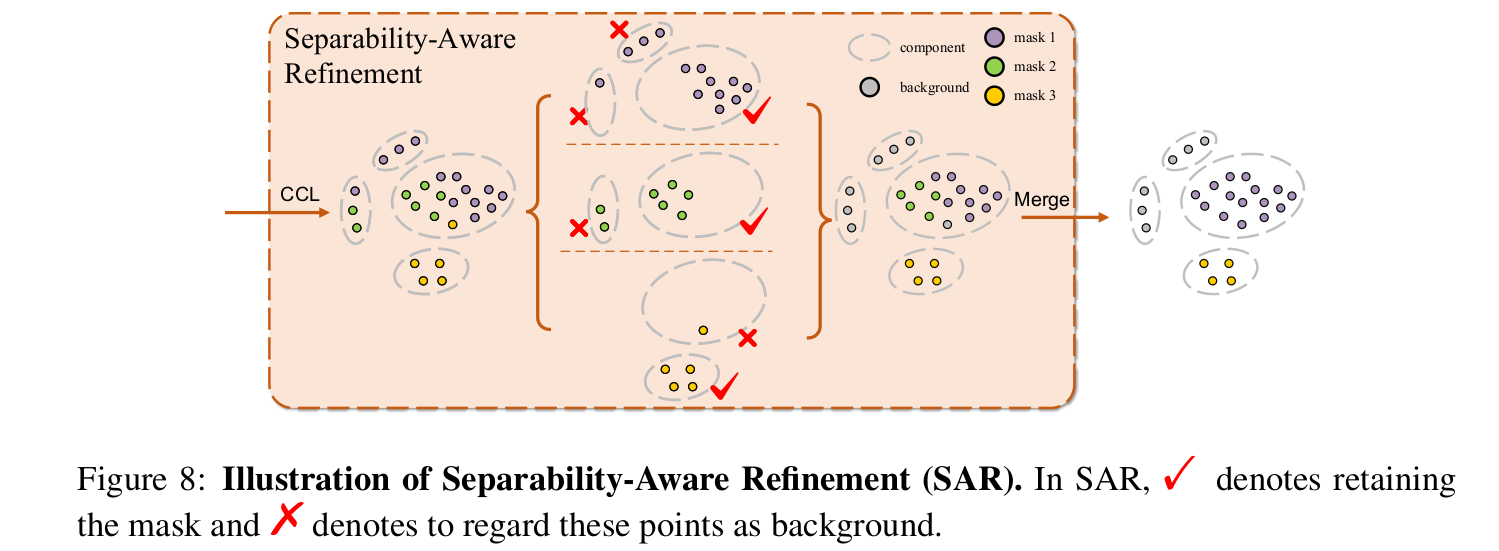
- Separability-Aware Refinement (SAR)
- 他のSAM-based worksへの批判もまとめられている
Experiment
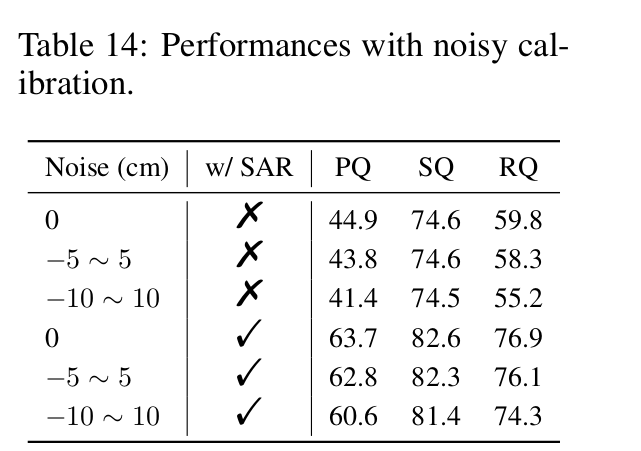
- 実験としてはboxに10%のノイズを食わせて疑似的にcoarse cluster labelにしている
- “MixSup follows a more practical philosophy to utilize different
types of supervision and tries to integrate them into popular detectors for generality”
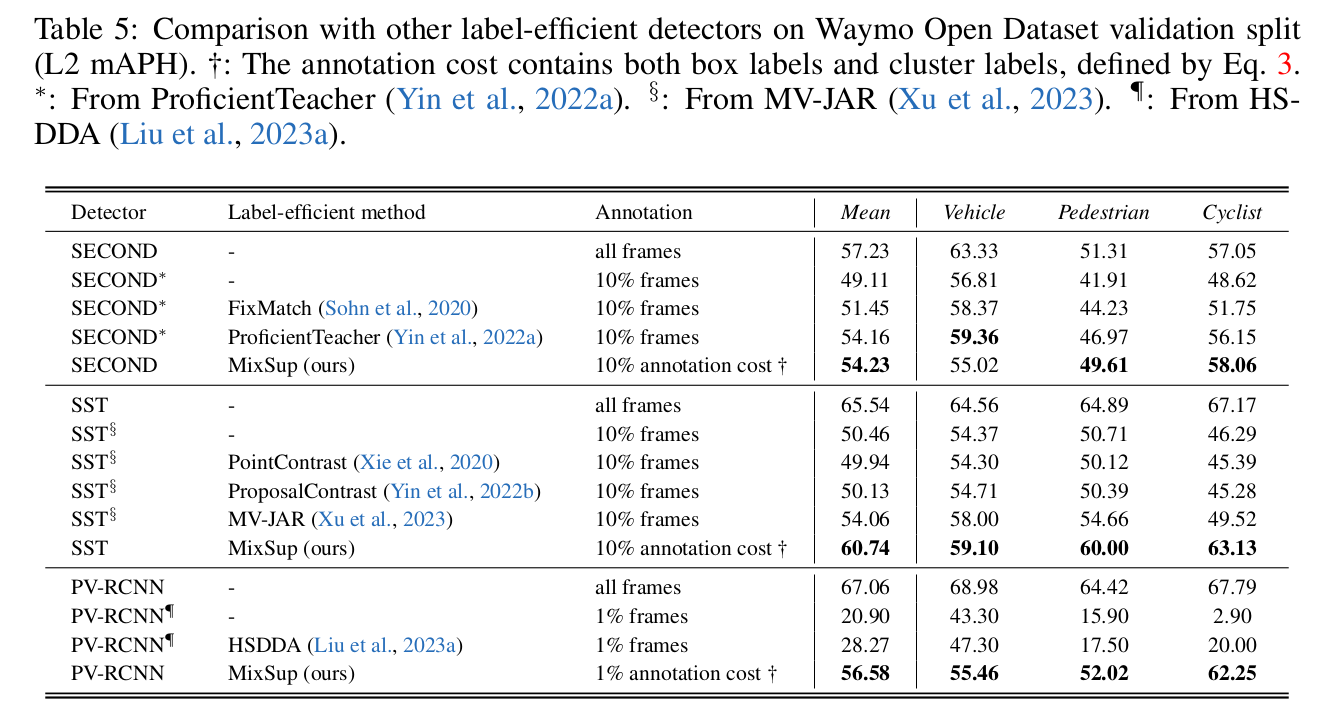
- 性能としてはかなり優秀な気がする、APHが下がっていないのも意外
- 10%のfull annotation + coarse labeling でほぼ100% annotationと同等
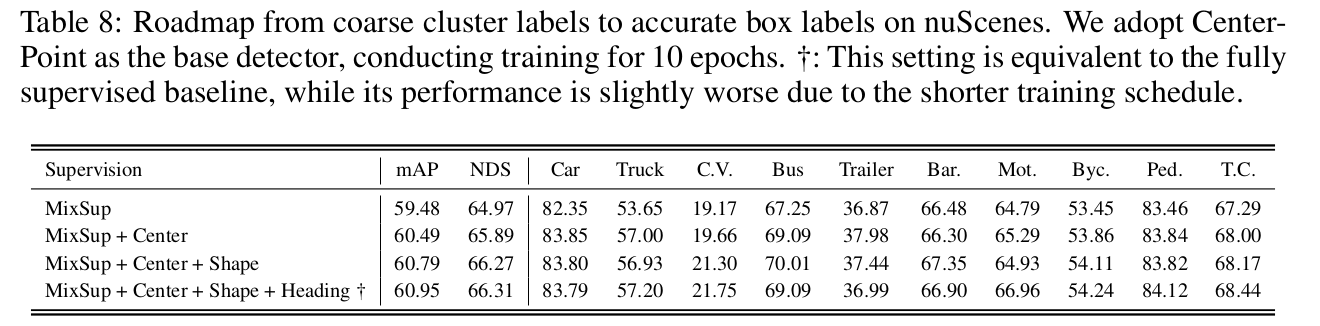
- CenterPoint base
- データが少ない時、classの多いnuScenesの方が性能は下がる
Discussion
- 3D detection baseのPseudo labelとしても、PointSAMみたいな別の手法baseの方が賢い気はする