Detecting As Labeling: Rethinking LiDAR-camera Fusion in 3D Object Detection (ECCV2024)
Summary
- from Phigent Robotics
- CTOが Baidu -> Horizon Robotics の経歴
- https://github.com/HuangJunJie2017/BEVDet
- Camera LiDAR 3D detection において、Camera pipelineはlabel推定にしか使わないようにした方が性能があがったという報告
Method
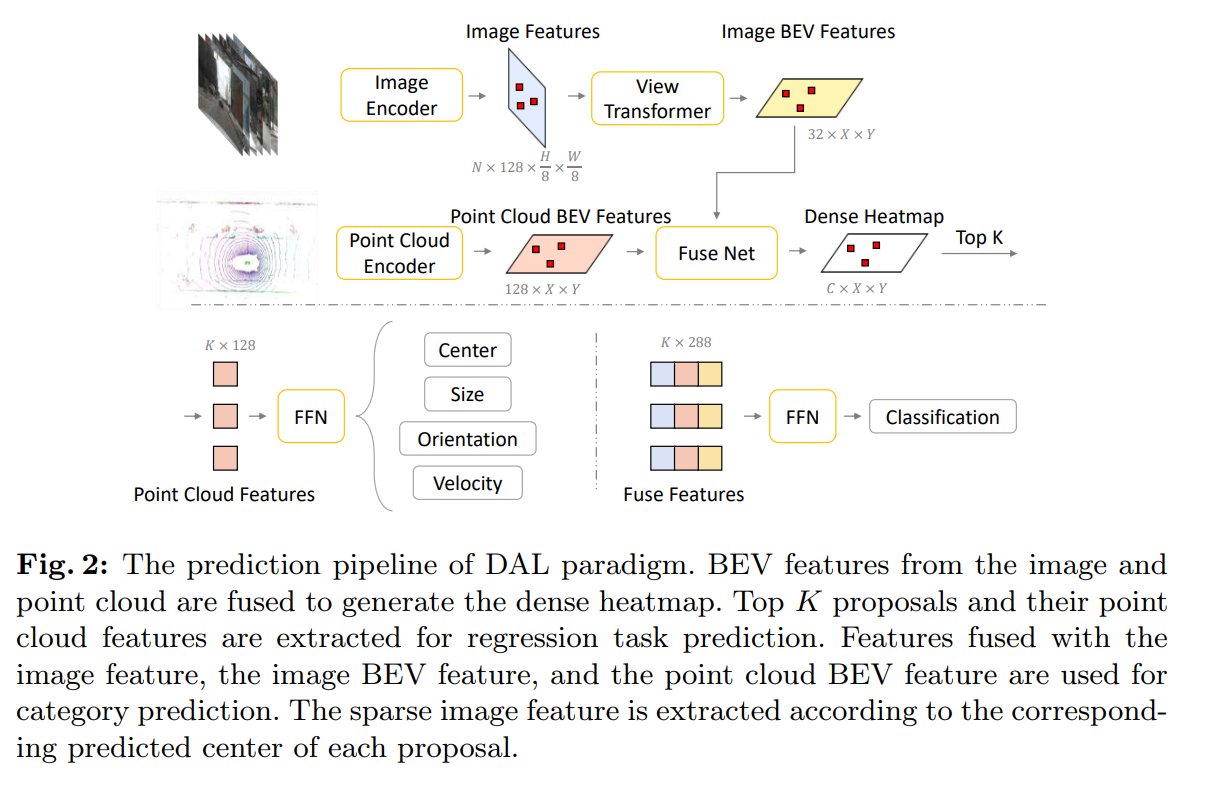
architecture
- Baseはアノテーション時の考え方から
- カメラでlabelを確認 -> pointcloudで位置・sizeを正確に捉えてBounding boxをアノテーションする
- そもそもカメラはlabelにしか使っていないのでは?
- pipeline
- Image BEV featureはclassificationにしか使っていない
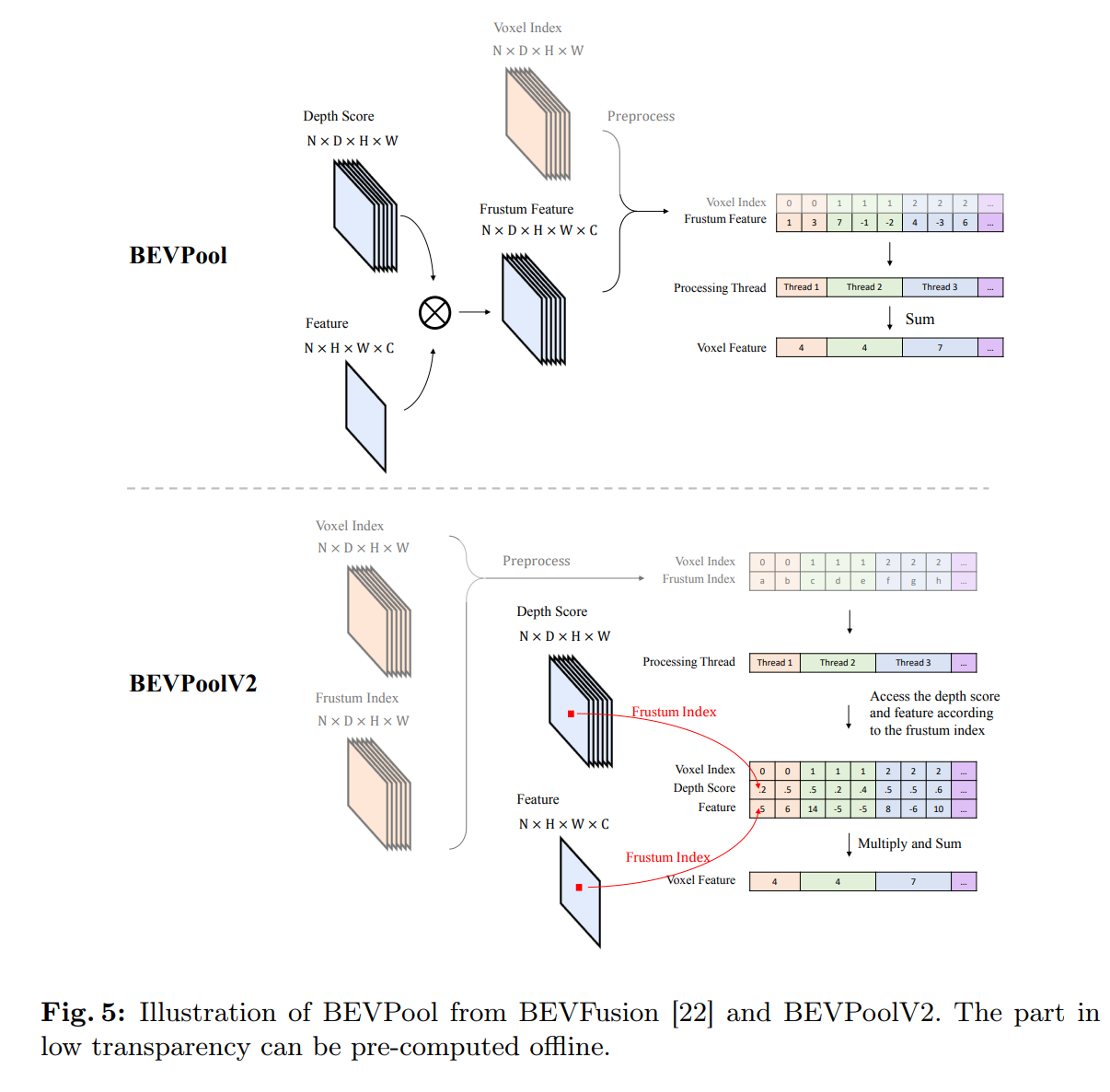
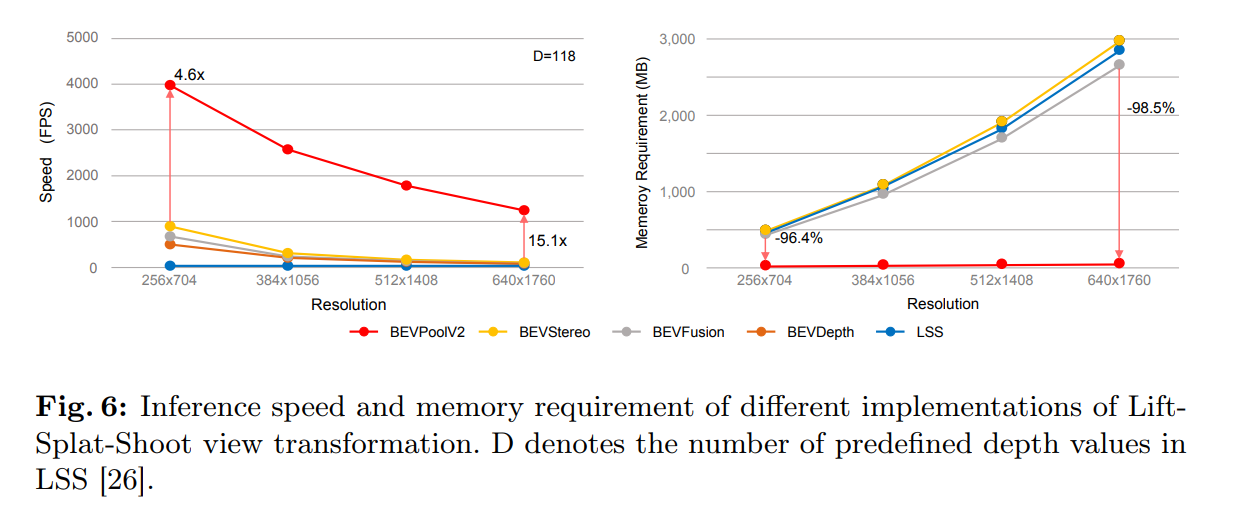
- BEVPoolV2.
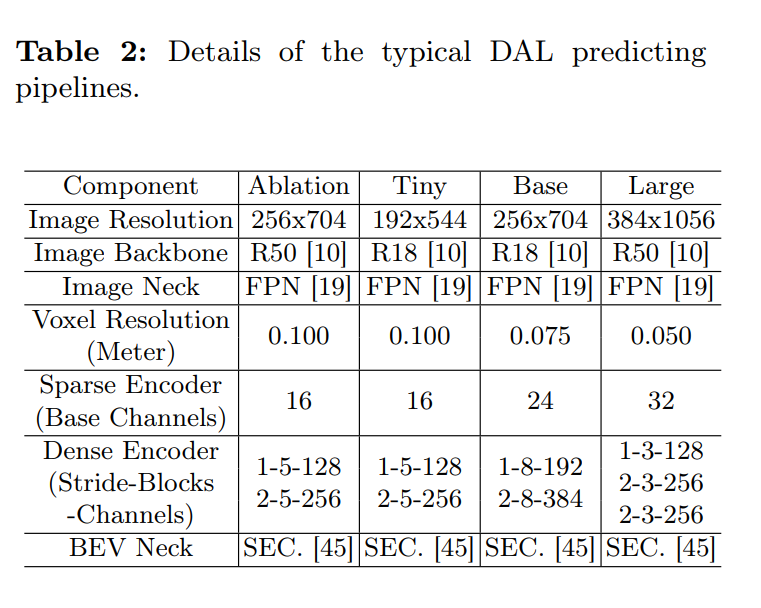
- parameter
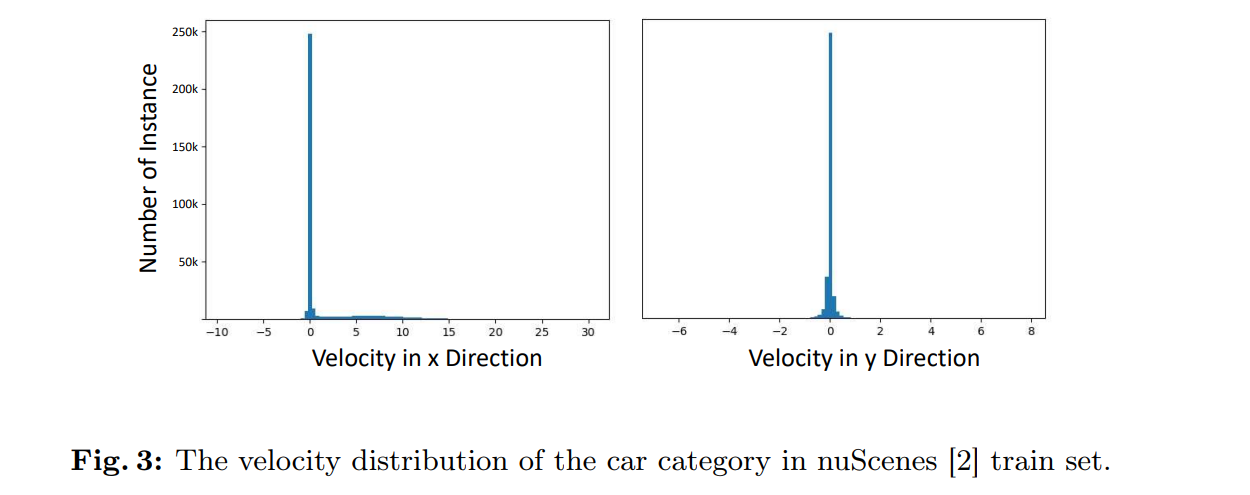
datasetの偏り
- nuScenesの分布
- かなりstatic objectが多い
- 速度を持っているとしてaugmentation

Experiment
- 学習:3090 * 16
- Camara-LiDAR fusion の一覧
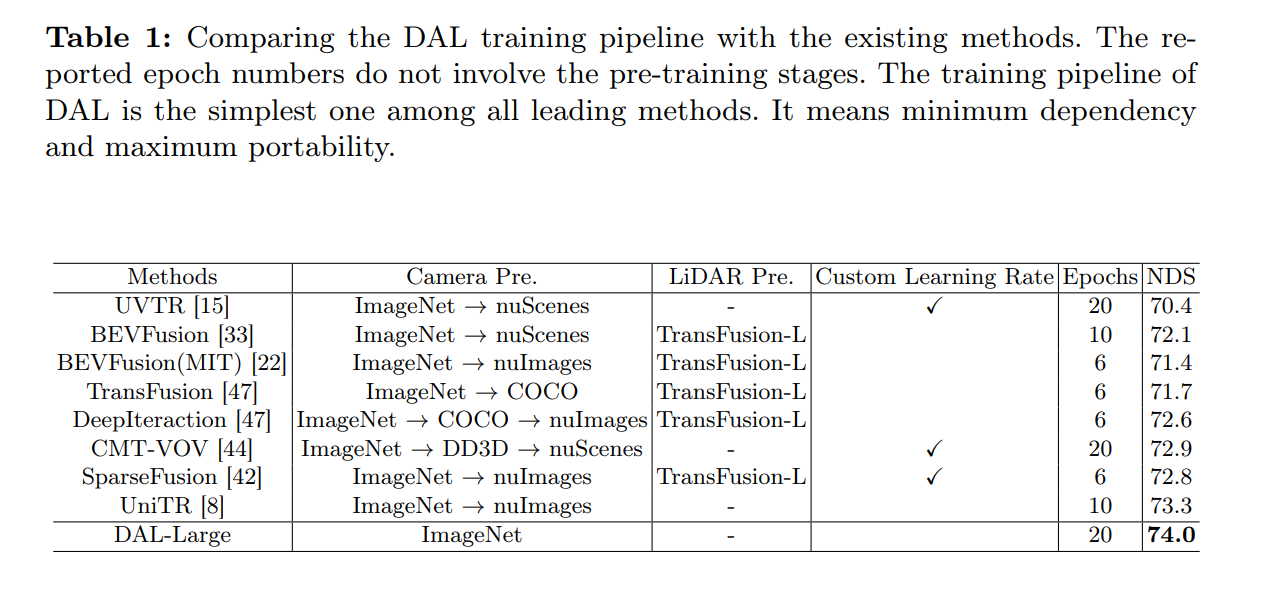
- 推論時間と性能
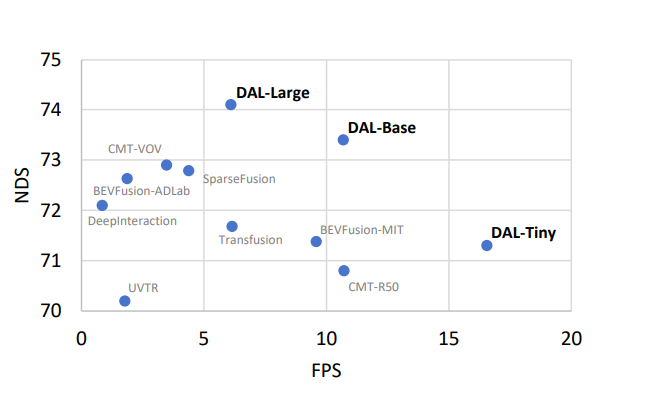
- 結果
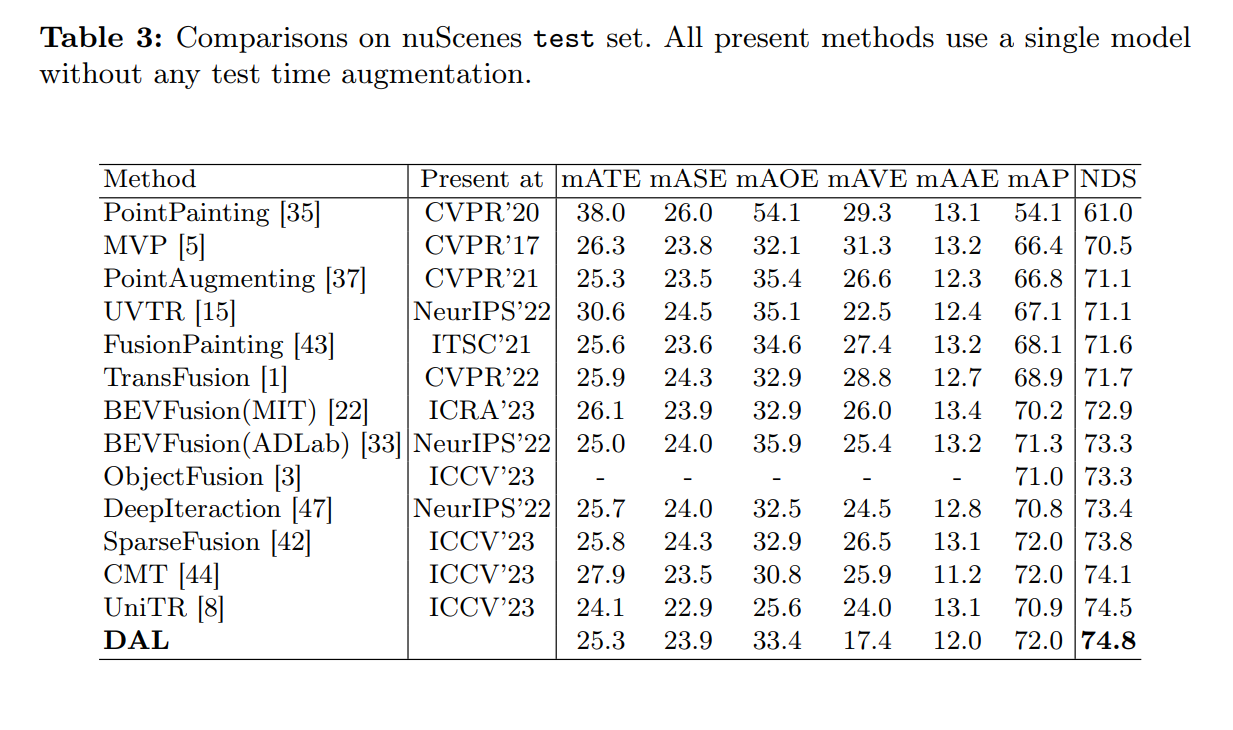
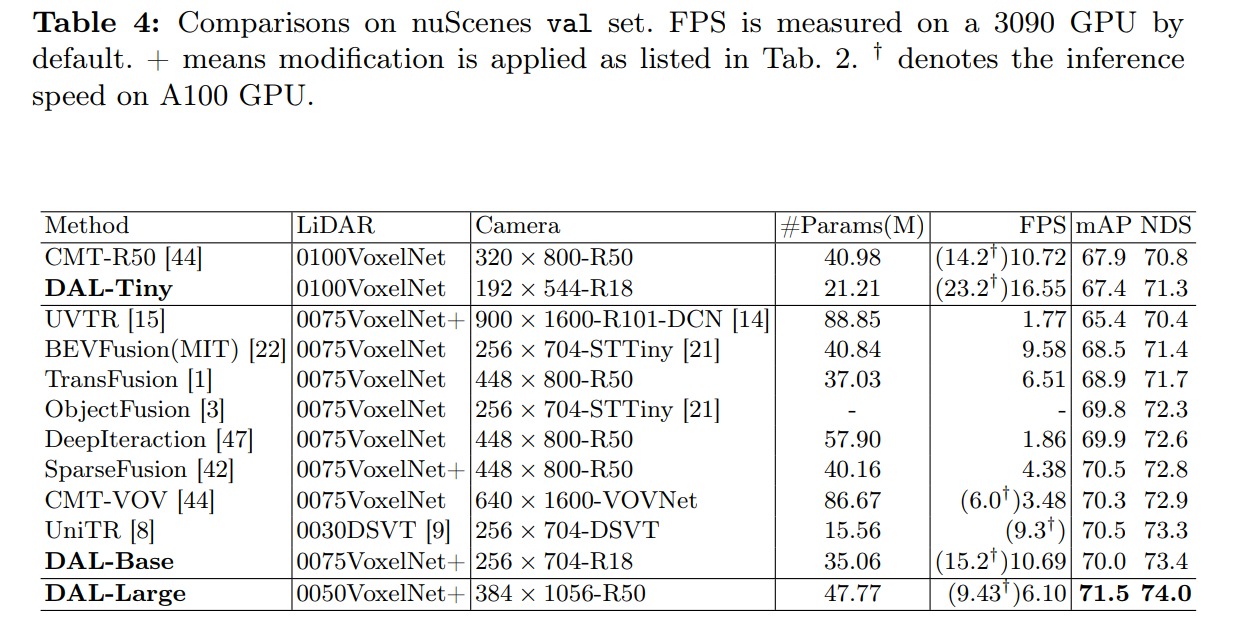
- LSS部分の改良
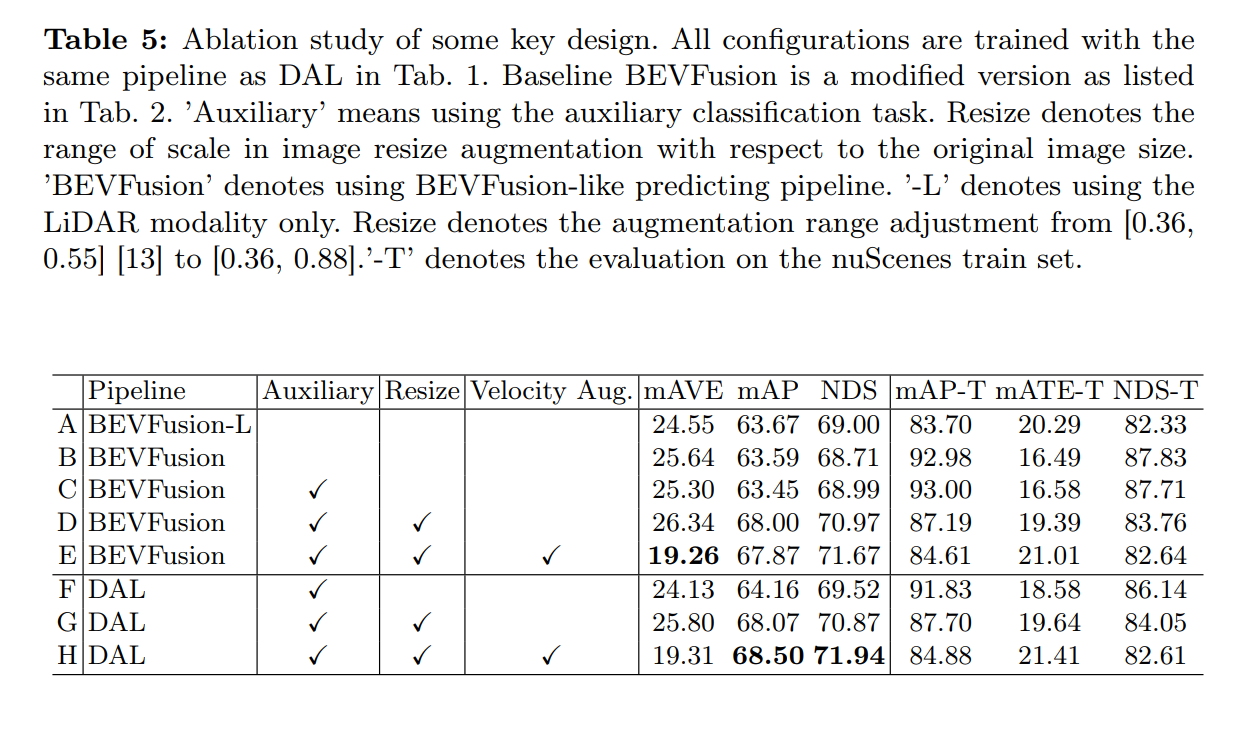
- velocity augmentationはmAVEに効いている
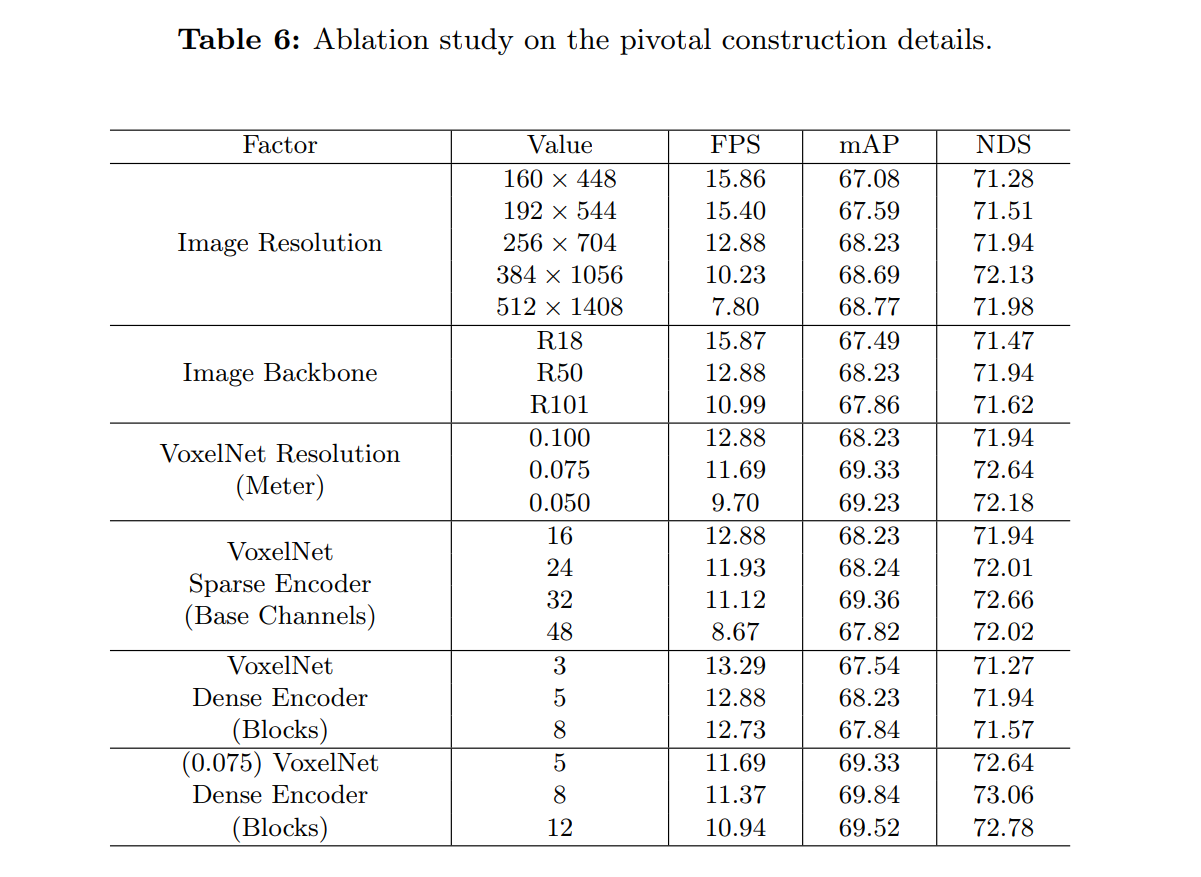
- 細かいtuning
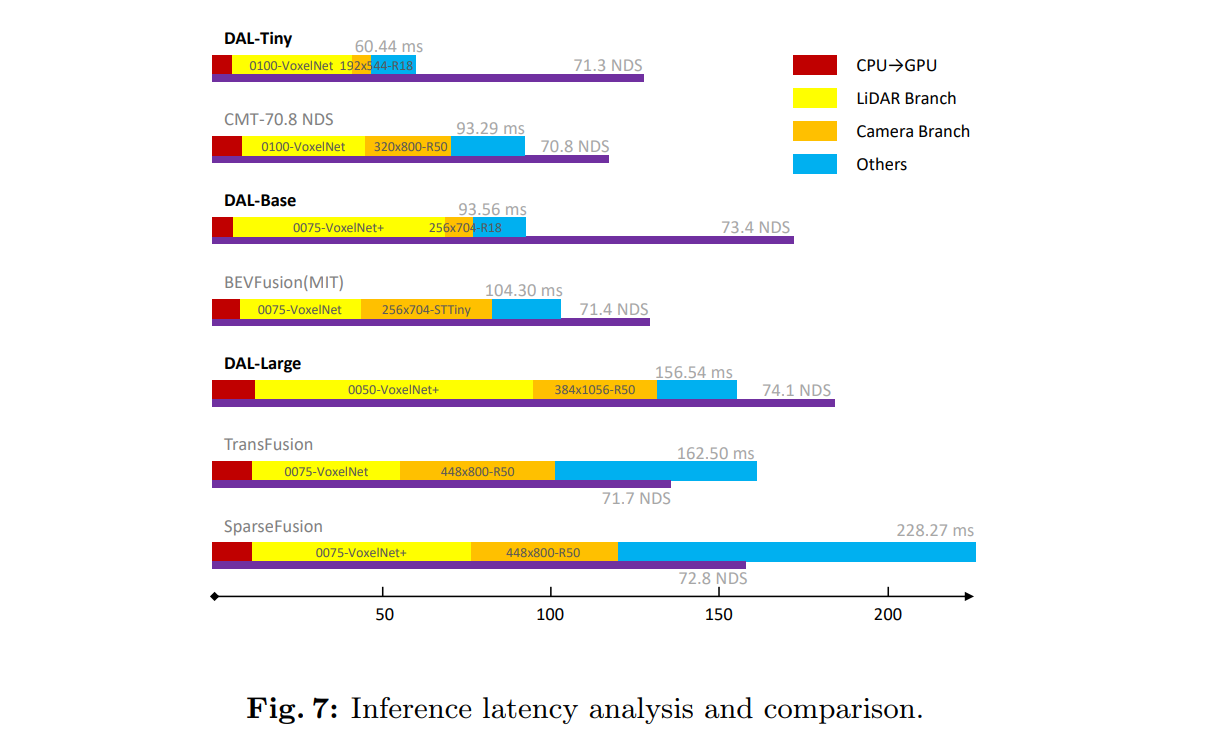
- Camera pipelineをできるだけ小さくして、LiDAR側を大きくするほうが性能のコスパが良い
Discussion
- LiDARまわり色々やってみたがあまりうまく行かなったとfuture workに書いてある
- nuScenesでの点群数が少ないからでは?