DRIVE VLM: The Convergence of Autonomous Driving and Large Vision-Language Models (arxiv2024/02, CoRL2024)
Summary
- https://github.com/Tsinghua-MARS-Lab/DriveVLM
- 2024/10/17現在未公開
- https://tsinghua-mars-lab.github.io/DriveVLM/
Method
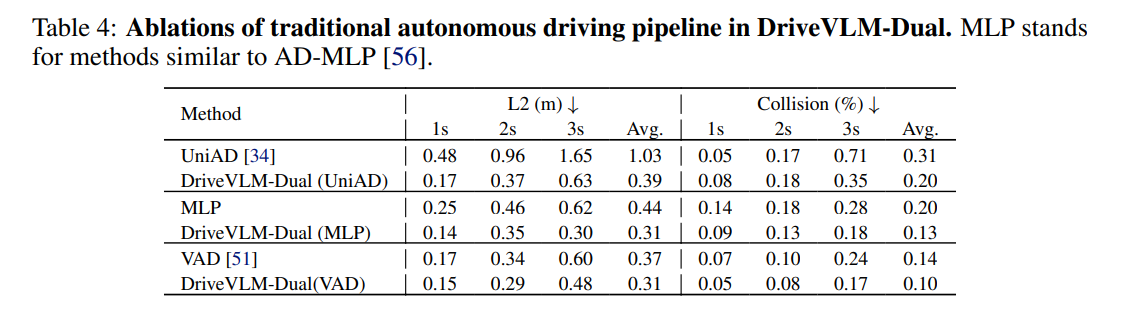
- DriveVLM-Dual architecture
- Output
- Meta-action
- Decision
- Waypoints
- Traditional pipeline = E2E model のこと
- Output
- Integrating 3D Perception.
- 2Dに投影して、critical objectとして扱えるようにする
- High-frequency Trajectory Refinement
- real-time, high-frequency inference capabilities のためにtrajectory refinement を行う
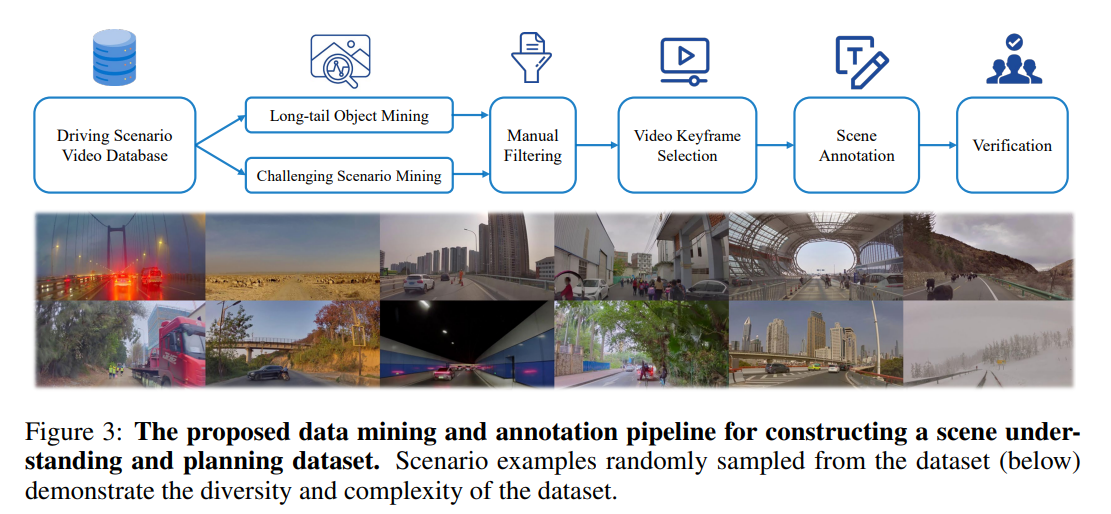
- Scene Understanding for Planning (SUP-AD) Dataset
Experiment
- https://youtube.com/watch?v=mt-SdHTTZzA
- おそらくLi autoの実験
- 実際に公道で実験できている、非常にレベルが高い
- Result
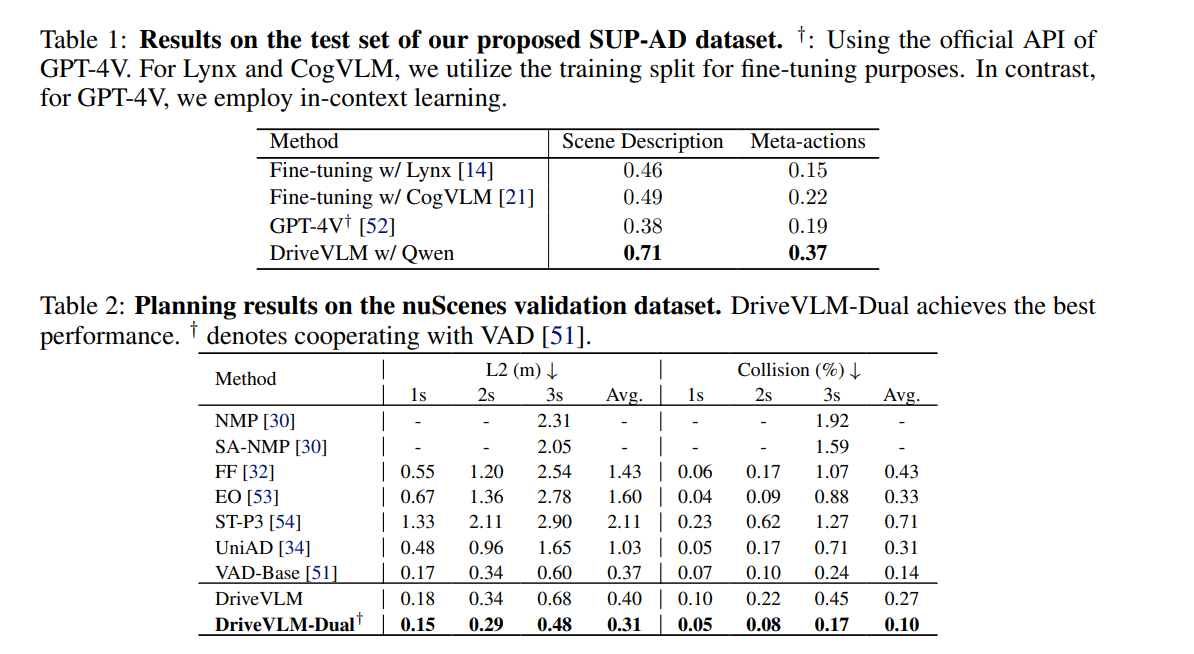
- System 1, 2はかなり寄与している