summary
- Cameraだけ/LiDARだけ/Camera-Lidarに対応している Sensor FusionのTracking フレームワーク
- (i) fusion of 3D and 2D evidence that merges detections belonging to the same object,
- (ii) two-stage matching that links detections across time to build tracks
- (iii) state update that enables motion forecasting
- (iv) a track lifecycle module that deletes obsolete tracks and reports information about confirmed ones
- github https://github.com/aleksandrkim61/EagerMOT
- https://www.youtube.com/watch?v=k8pKpvbenoM
- 前身の論文がICAR2020 Workshopに通っている
- EagerMOT: Real-time 3D Multi-Object Tracking and Segmentation via Sensor Fusion Aleksandr Kim, Aljoša Ošep, Laura Leal-Taixé
- https://motchallenge.net/workshops/bmtt2020/
- https://motchallenge.net/workshops/bmtt2020/papers/EagerMOT.pdf
- アルゴリズムは同じ、実験の内容が増えただけ
Background
Method

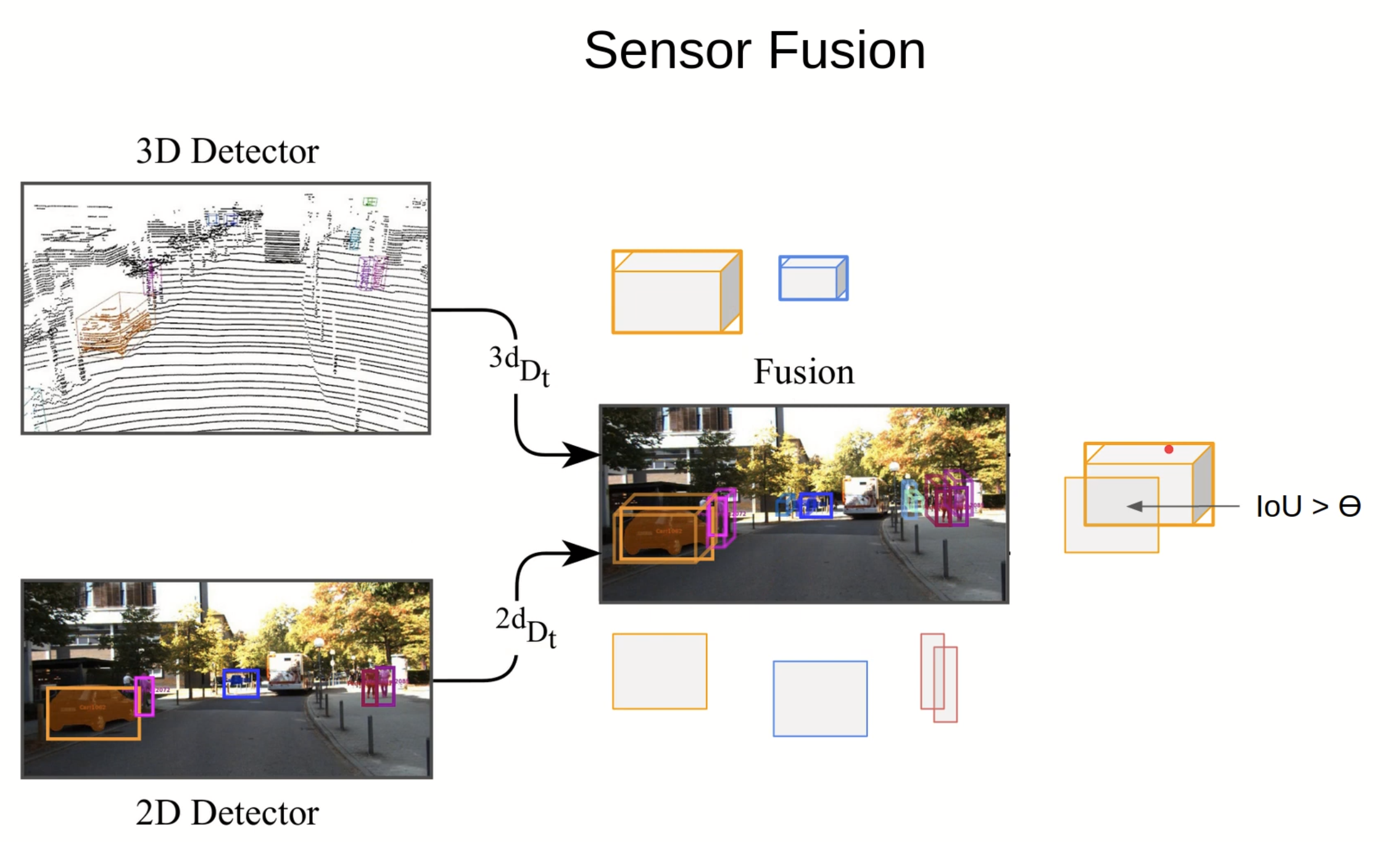
1. Sensor Fusion
- input
- $ ^{2d} D _ t $: 2d detection
- Option: $ ^{2d} D ^ i _ t $ : 2d Instance segmentation
- $ ^{3d} D _ t $: 3d detection
- output
- $ ^{2d} I _ t $: 2d Instance
- $ ^{3d} I _ t $: 3d Instance
- 3d detector -> 2d化
- 2d空間内でハンガリアンの計算して Instance $ I _ t = \lbrace I ^ 0 _ t, .., I ^ i _ t \ \rbrace $
- cost matrixはIoU in 2dのIoU
- comment: ここは2d使っている場合は2d内のIoU、3dのみの場合は3dにおける重心の距離とかで良い気がする
- cost matrixはIoU in 2dのIoU
- その後 3D 2Dに復元する = Instance
- ハンガリアンを使って2Dと3Dをmatchingする
- 2d空間内でハンガリアンの計算して Instance $ I _ t = \lbrace I ^ 0 _ t, .., I ^ i _ t \ \rbrace $
- Option:MOTS
- Instance Segmentaionを使ってのIoU計算も可能
2. Joint Instance/Track
- Trackingしていた $T _ {t - 1} $てものとdetectionで取れたInstanceを結合するレイヤ
- 3dのみ $ ^{3d} T _ {t - 1} \subseteq T _ {t - 1} $
- 2dのみ $ ^{2d} T _ {t - 1} \subseteq T _ {t - 1} $
- both $ ^{both} T _ {t - 1} \subseteq T _ {t - 1} $
- それぞれありうる
1st data association
-
AB3DMOTと同様
-
input
- $ ^{3d} I _ t $: 3d instance
- $ ^{3d} T _ {t - 1} $: 3d tracked object
-
output
- updateに突っ込む
- $ ^{1m} IT _ {t} $: t-1 frameまでtrackedしており、t frameでも検知できたinstance
- $ ^{1u} I _ t $: t-1 frameまでtrackしていない新しいinstance
- $ ^{1u} T _ t $: t-1 frameまでTrackingできていたが、t frameで検知できなかったinstance
- updateに突っ込む
-
Hungarianを用いて $ ^{3d} I _ t $ + $ ^{3d} T _ t $
- 正確には$ \hat{ ^{3d} T _ t} $という表記が良い気がする
- KF baseで $ ^{3d} T _ {t - 1} $から$ \hat{ ^{3d} T _ t} $を推定する
-
matchしたペア $^{1m} IT _ {t} = \lbrace (I ^ i _ t, T ^ j _ t), .. \rbrace $
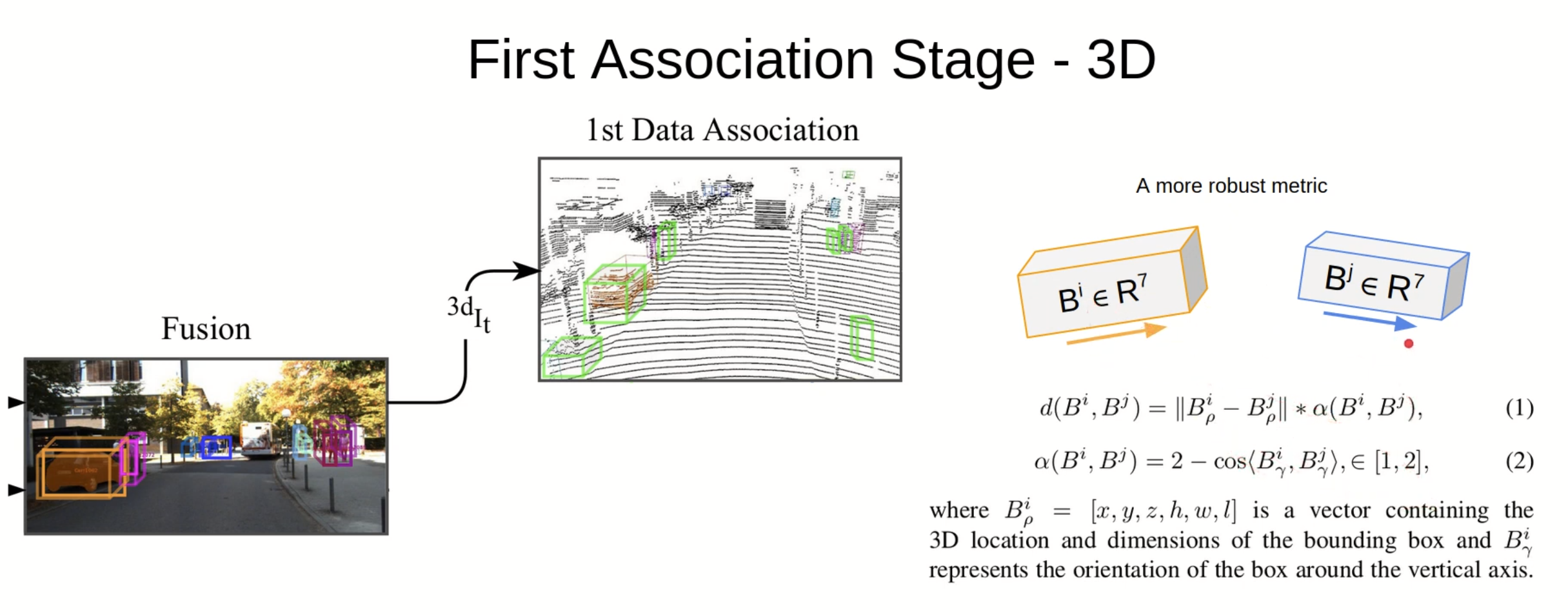
- distanceの定義
- $ B ^ i _ ρ = (x, y, z, h, w, l) $
2nd data association
- 2 stage目は3dから落ちるようなobject、画像だけでtrackingできているものを拾うためのmodule
- input
- $ ^{1u} T _ t $: t-1 frameまでTrackingできていたが、t frameで検知できなかったinstance
- t-1 frameまでTrackingできていた3d objectを2dへ投影、2dの中でIoU取って
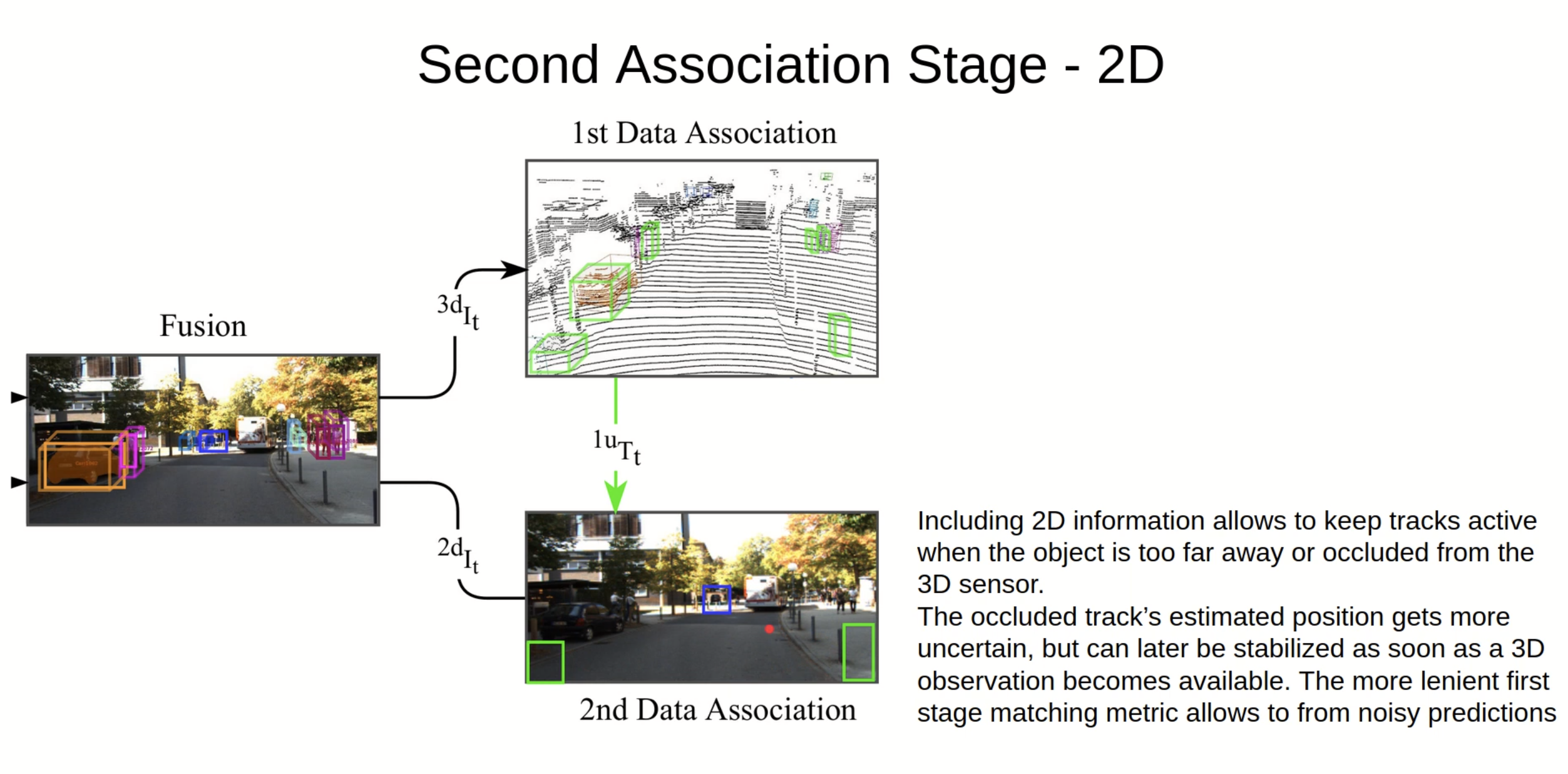
- 特徴としては
- Occulusionがあって点群では見えにくいものが拾える
- lidarの死角もtrackingに追加できる
- 画像だけで捉えられている遠距離もtrackingできる
3. tracking update
- Track lifecycle

- (i) All tracks erase their 2D information;
- (ii) Matched instances update their states: new measurements for 3D Kalman filters and new 2D states;
- (iii) Unmatched instances start new tracks.
Experiment
- nuscenes, kittiで評価
- CVPRWorkshopの時はkittiのみ
- この2つで評価されているそこそこきれいなコードがある
- 使ったモデル
- 3D detection
- CenterPoint for nuscenes
- PointGNN for kitti
- 2D detection
- Cascade RCNN for nuscenes
- RRC for kitti kitti car
- Track R-CNN for kitti pedestraion
- datasetによってモデルが違うのは少し気になるな・・・
- 3D detection
- 90 FPS on a commodity CPU
- 2d / 3d MOTでSOTA
- 様々な比較
- 2dobject detectionの情報を入れているのが大きい
- 2D distanceはdetectionの情報をいれずに画像空間内のdistanceを用いるということ
- 3d detectionや 2d detectionは大体一緒

Discussion
- simple, multi-modalをsimpleに扱えている
- Lidarのみ/Cameraのみ/Fusionそれぞれで動きそうなFramework
- 拡張性高いフレームワーク + OSS化されている
- 評価のところは参考にできそう
- 読めるコードでnuscenesで評価されているので非常に参考になるはず