BEVFormer: Learning Bird’s-Eye-View Representation from Multi-Camera Images via Spatiotemporal Transformers (ECCV2022)
Summary
- https://github.com/fundamentalvision/BEVFormer
- Attention base でのMulti-cameraからBird’s-Eye-View Representation を得る研究
- 最近の流行りになったきっかけの一つ
Method
- やっていることはtransformerの形にどう食わせるかっていうだけ
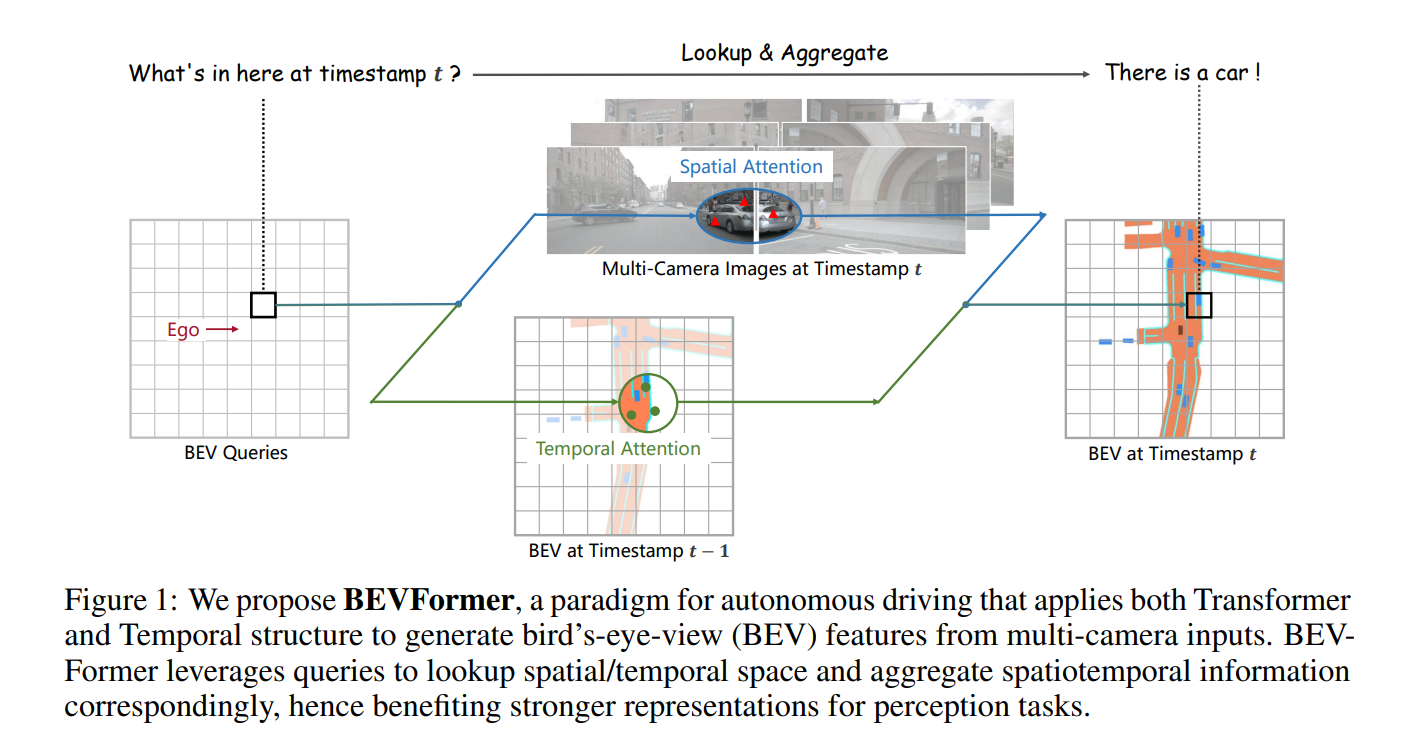
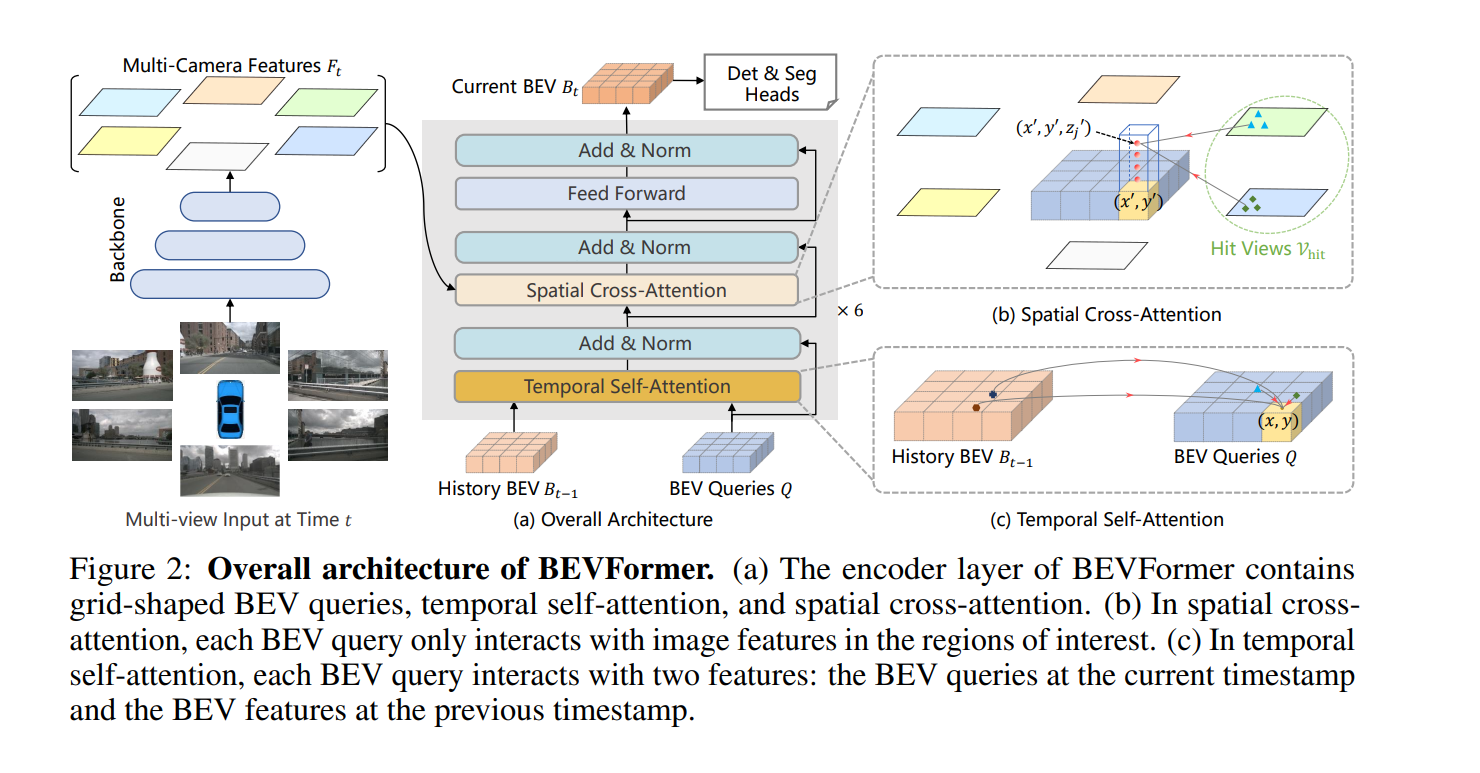
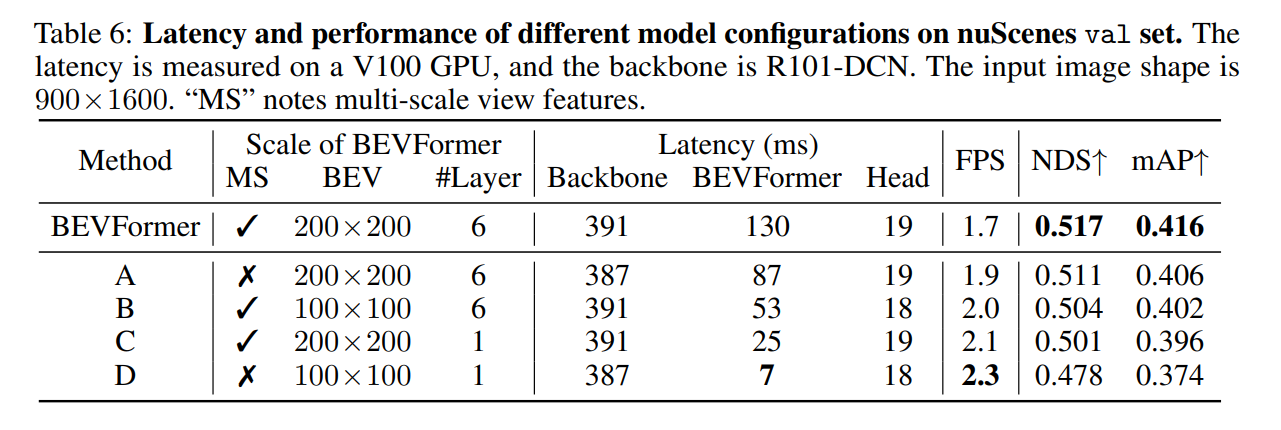
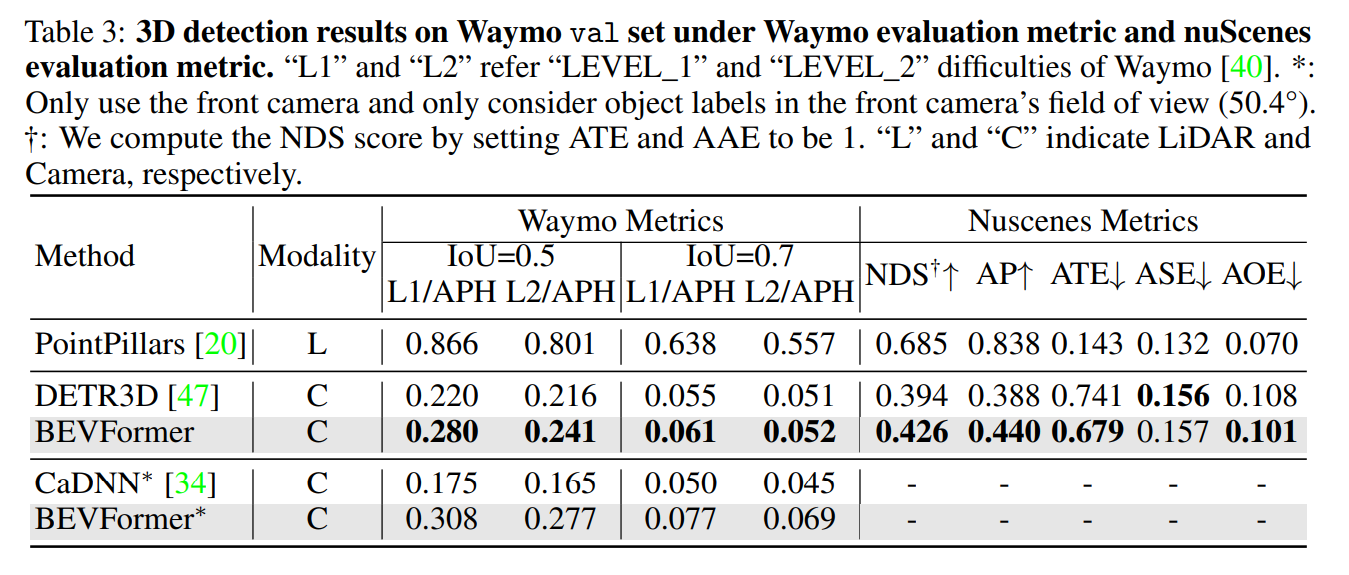
Experiment
- これからのbaseline
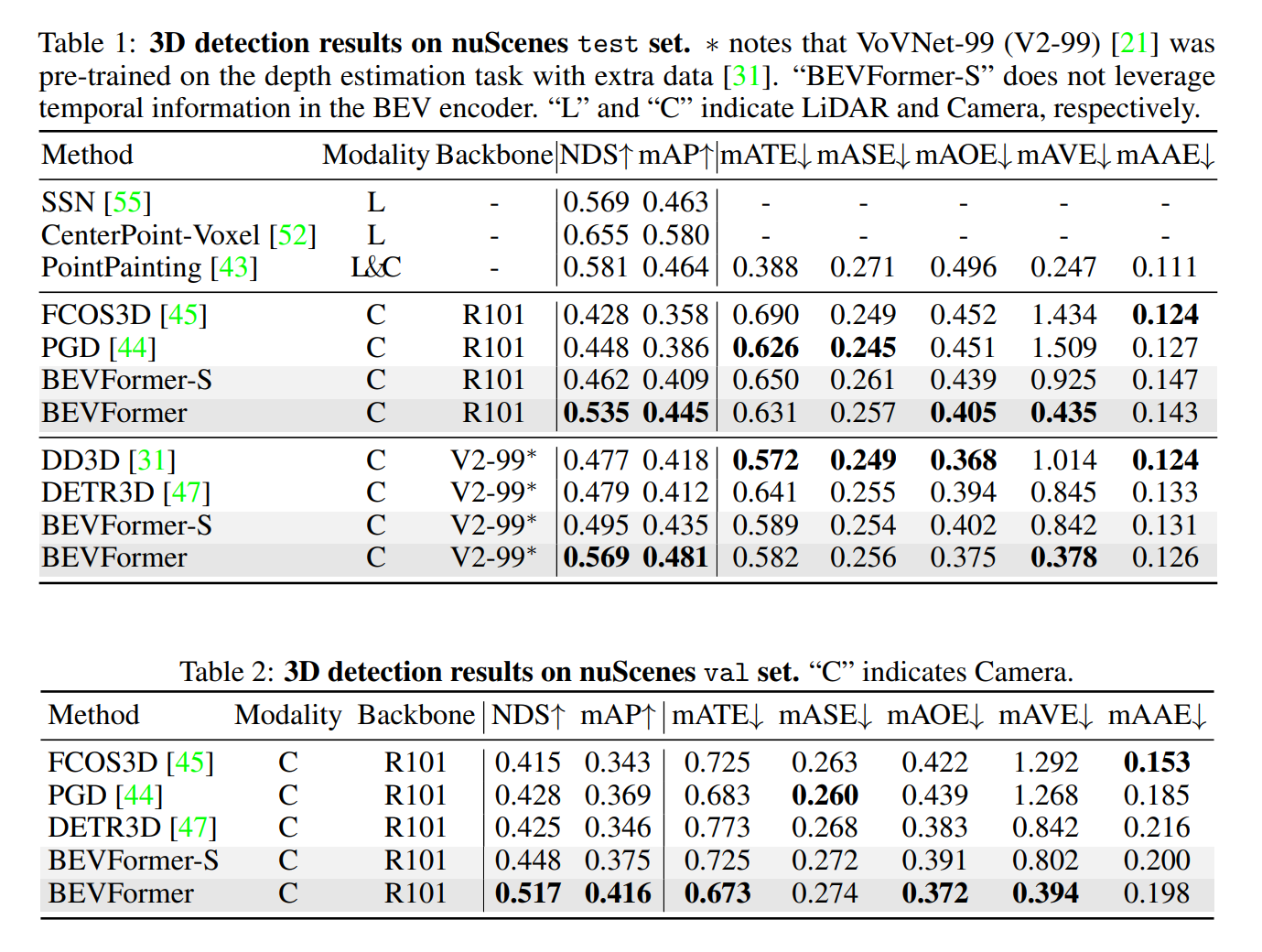
- V100で2fpsとかなので、Robot用途だと結構厳しい