Summary
- https://arxiv.org/pdf/2205.09743.pdf
- https://github.com/zhangyp15/BEVerse
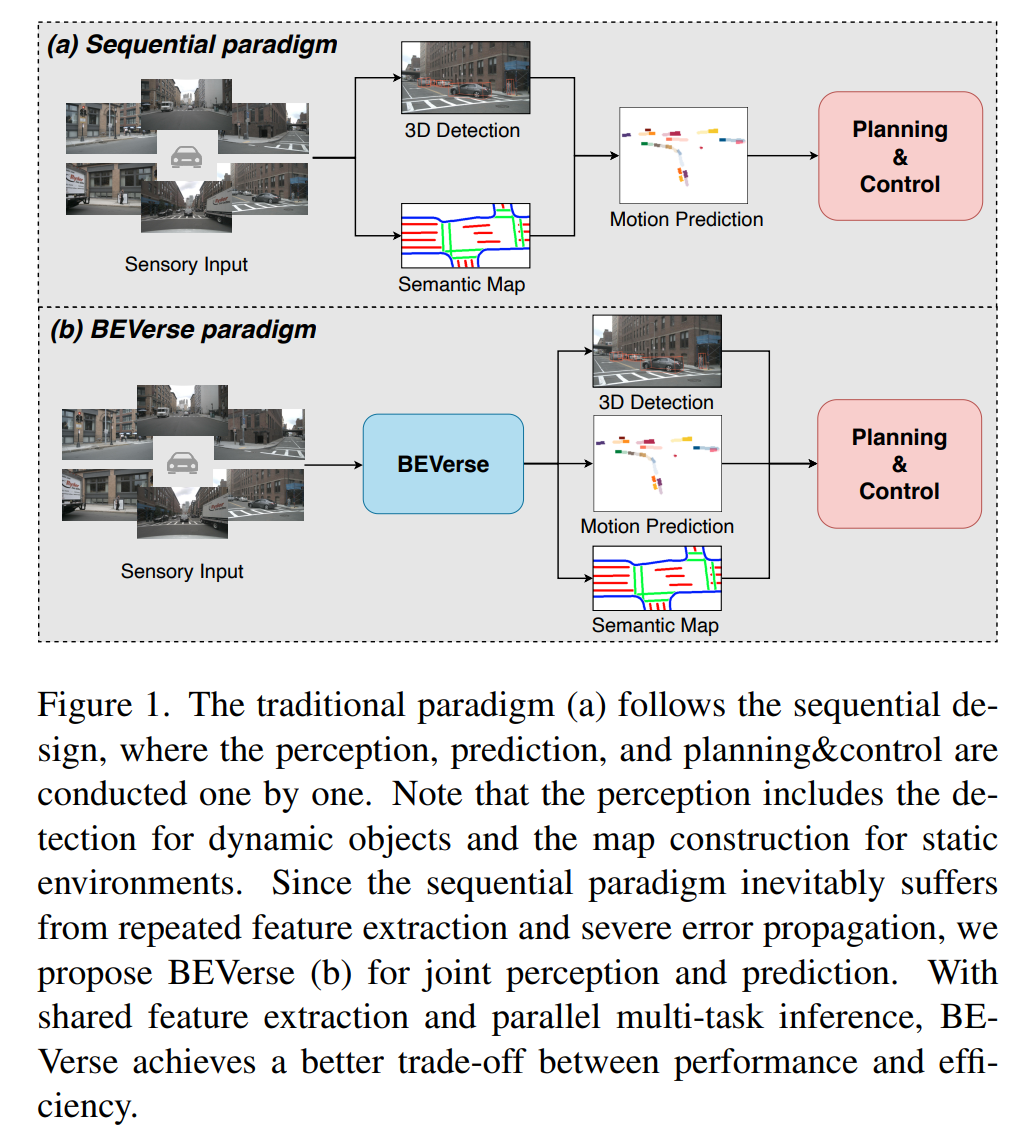
- Multi-Camera BEV perception
- 3d detection, motion prediction, semantic map のmulti-task learning
- semantic map は mapのみでobjectは含まない
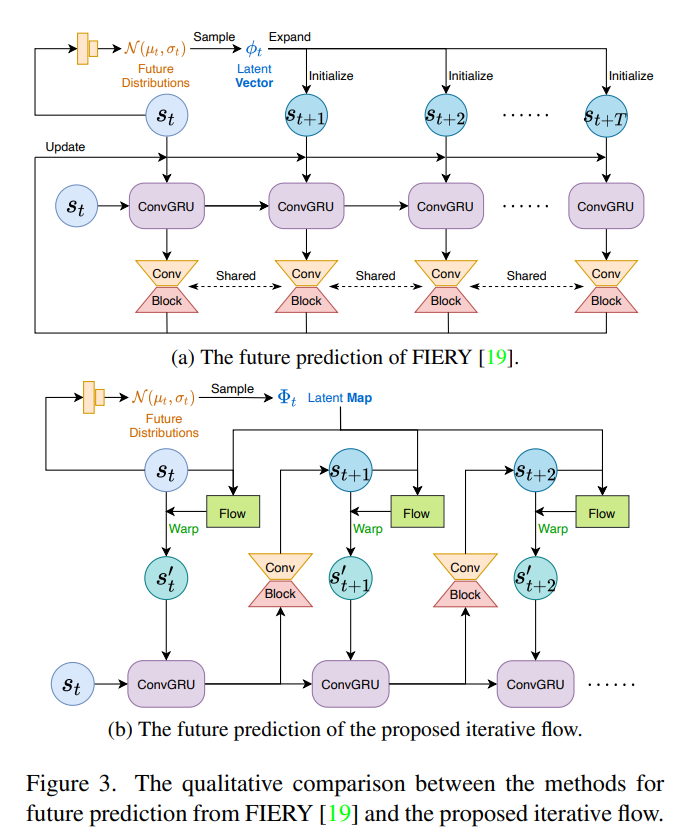
- motion prediction はsegmentationの表現で行われている
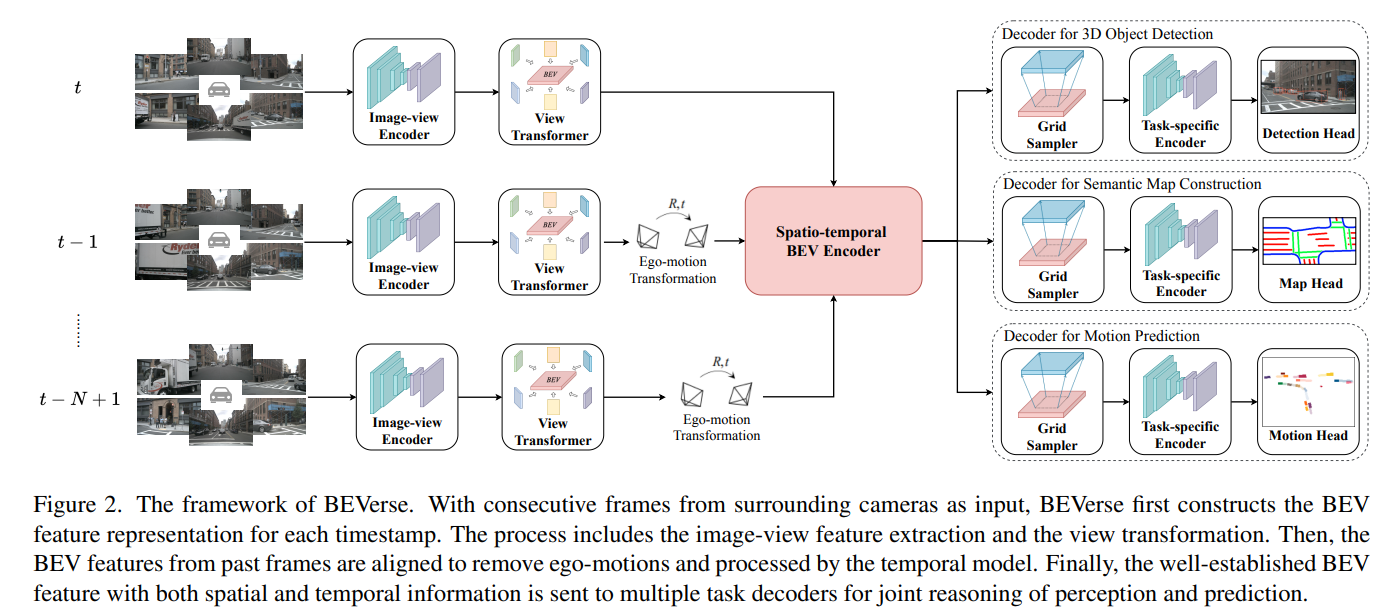
- Multi-frame, transformer base
- Encode-decode した後transformerでBEV featureにする
- BEV feature * n frame
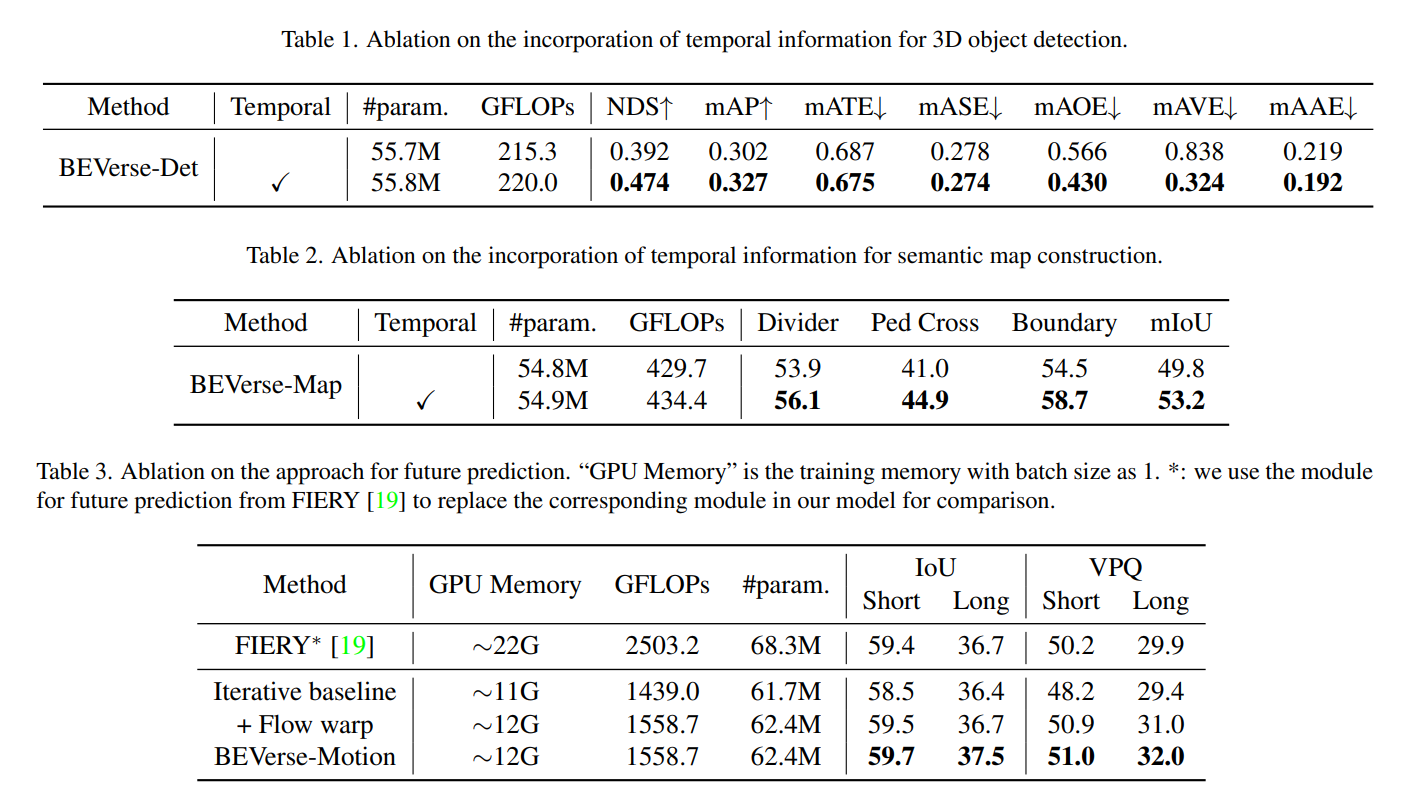
- detectionだけならRTX 3090 GPUs, 12.6fpsで意外と利用に耐えうるレベル
- ただmulti task modelだと4.4fpsなので微妙
- motion prediction が重い
Methods
Experiment
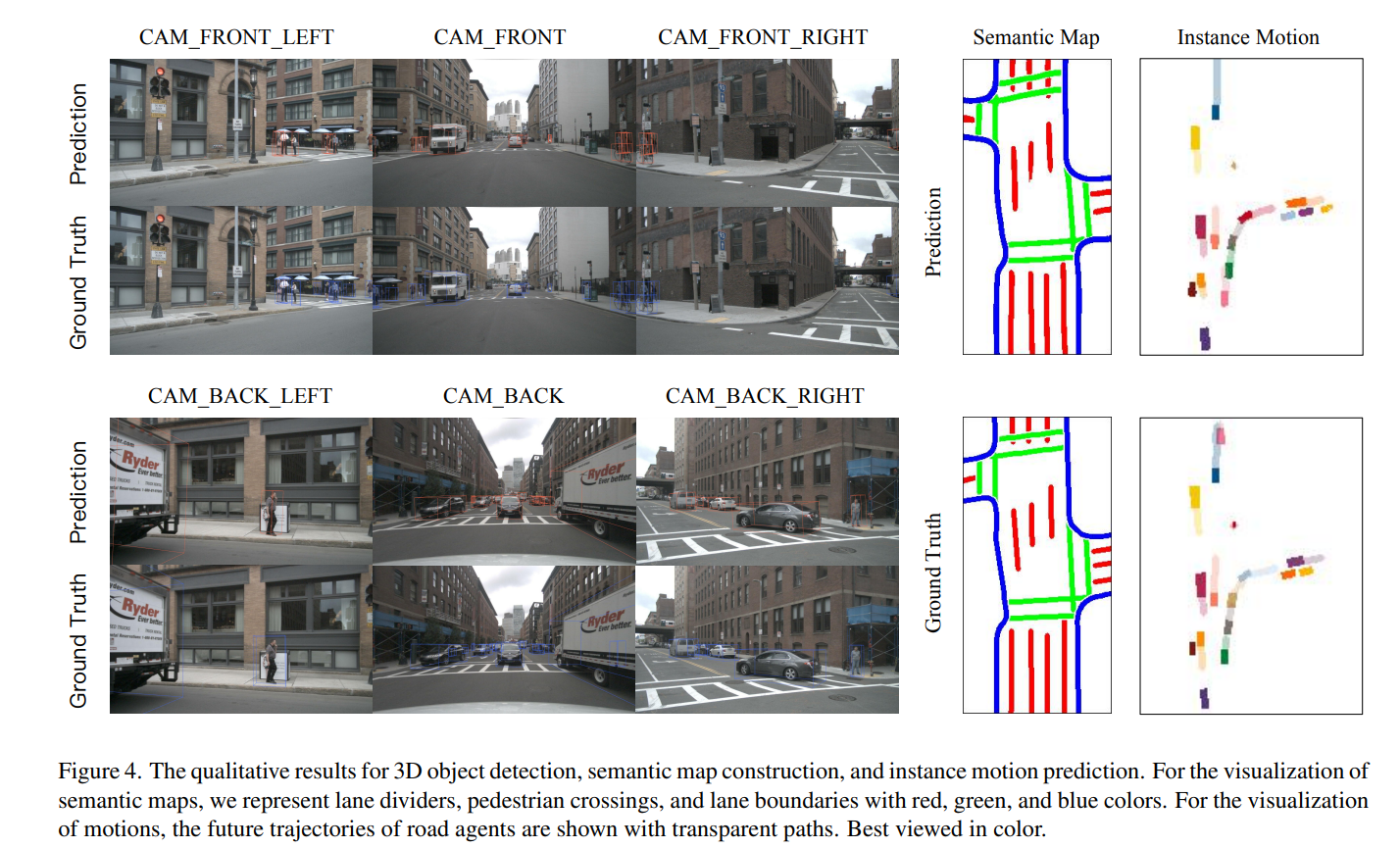
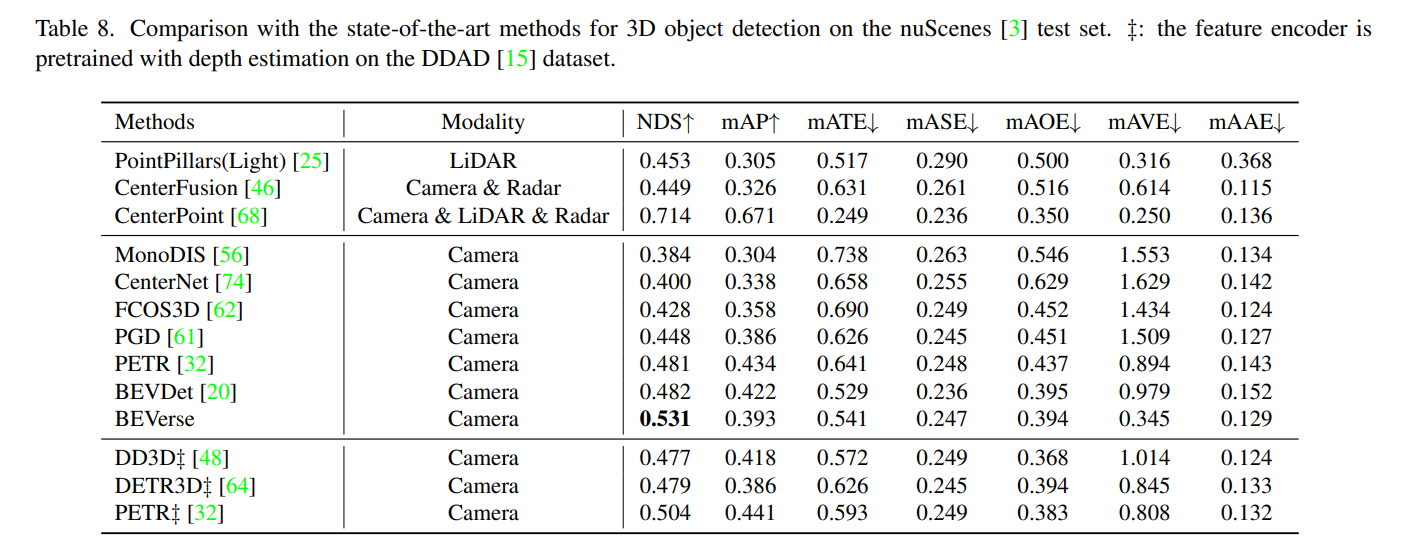
- 共通model
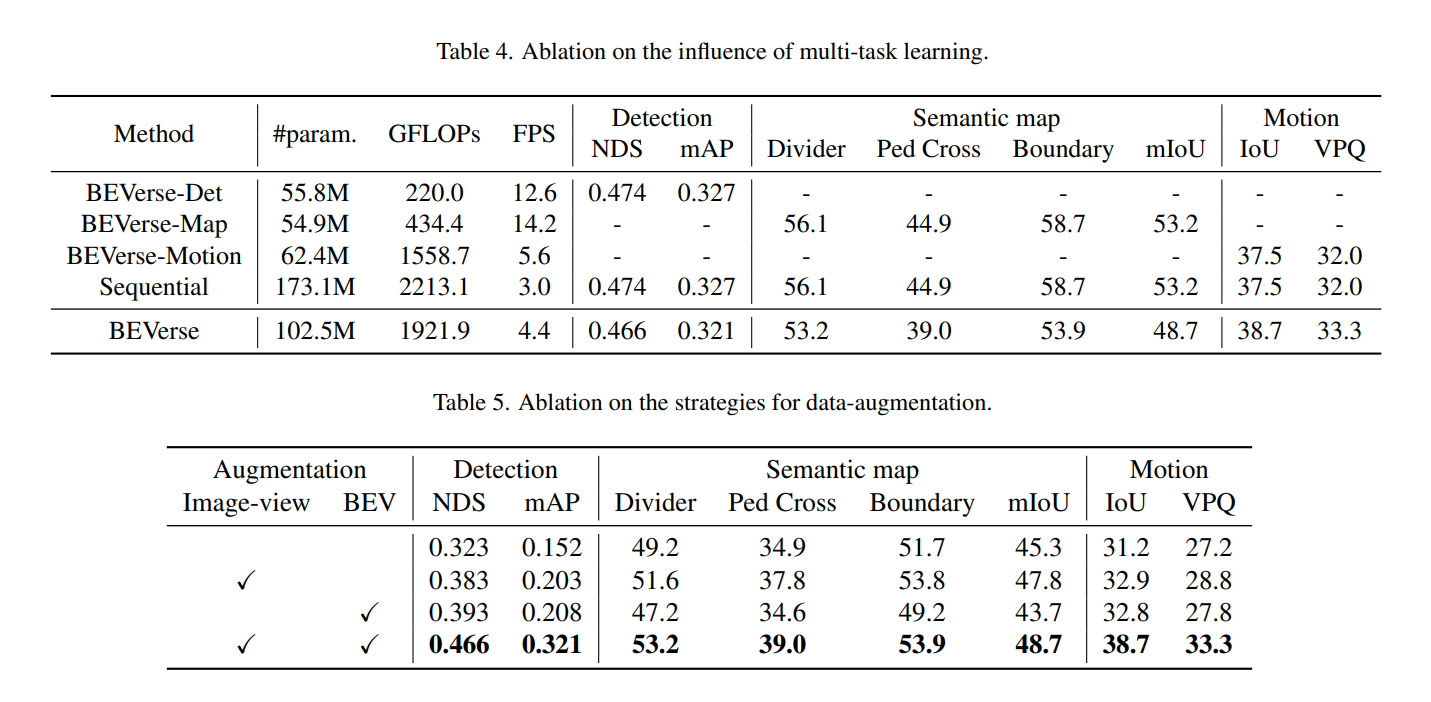
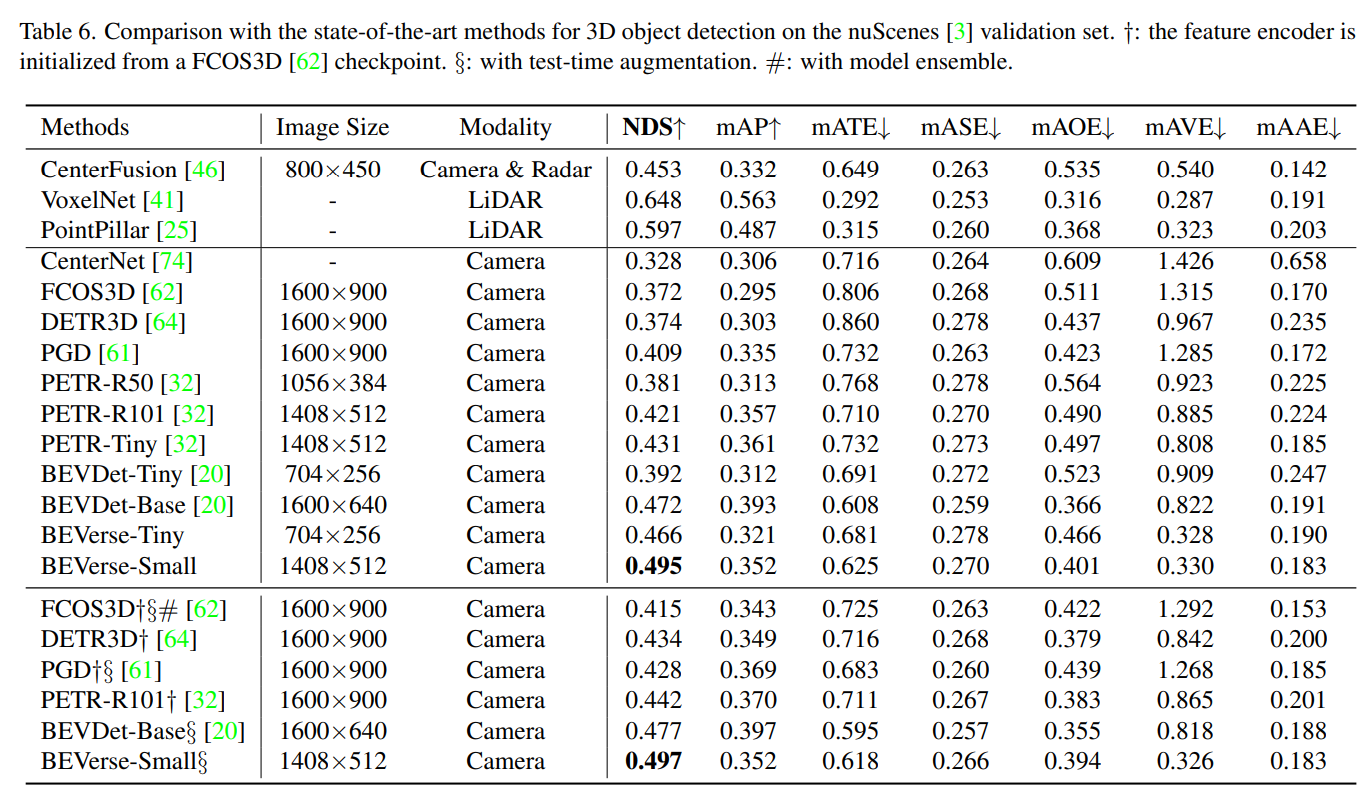
- BEVerse-Det 55.8M param, 12.6fps = 80ms
- 全部載せだと102.5M param, 4.4fps で流石に重い
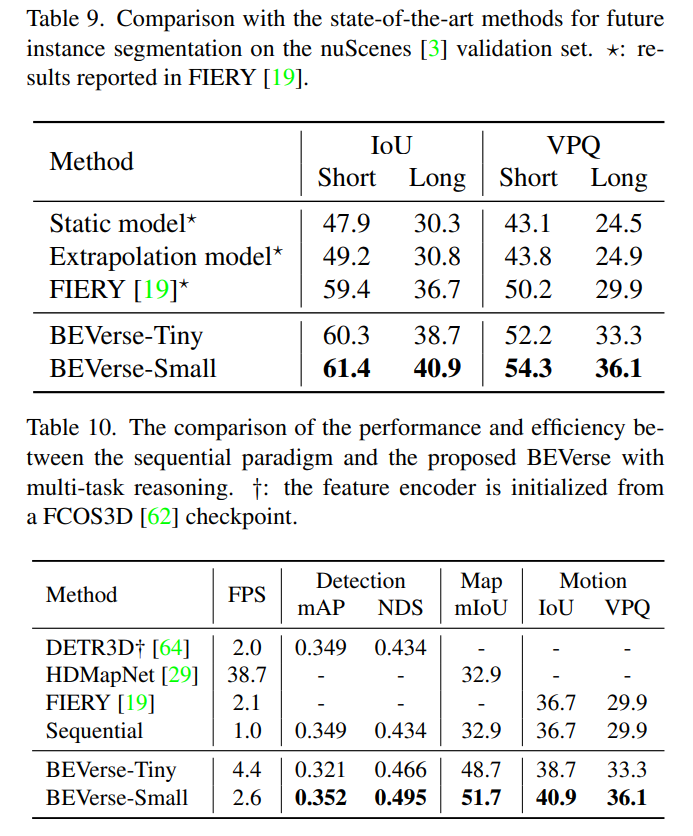
- Future instance segmentation