Depth Anything: Unleashing the Power of Large-Scale Unlabeled Data (arxiv 2024/01)
Summary
Background
- multi-dataset joint training
- MiDaS: relative depth information
- ZoeDepth も強いらしい
Method
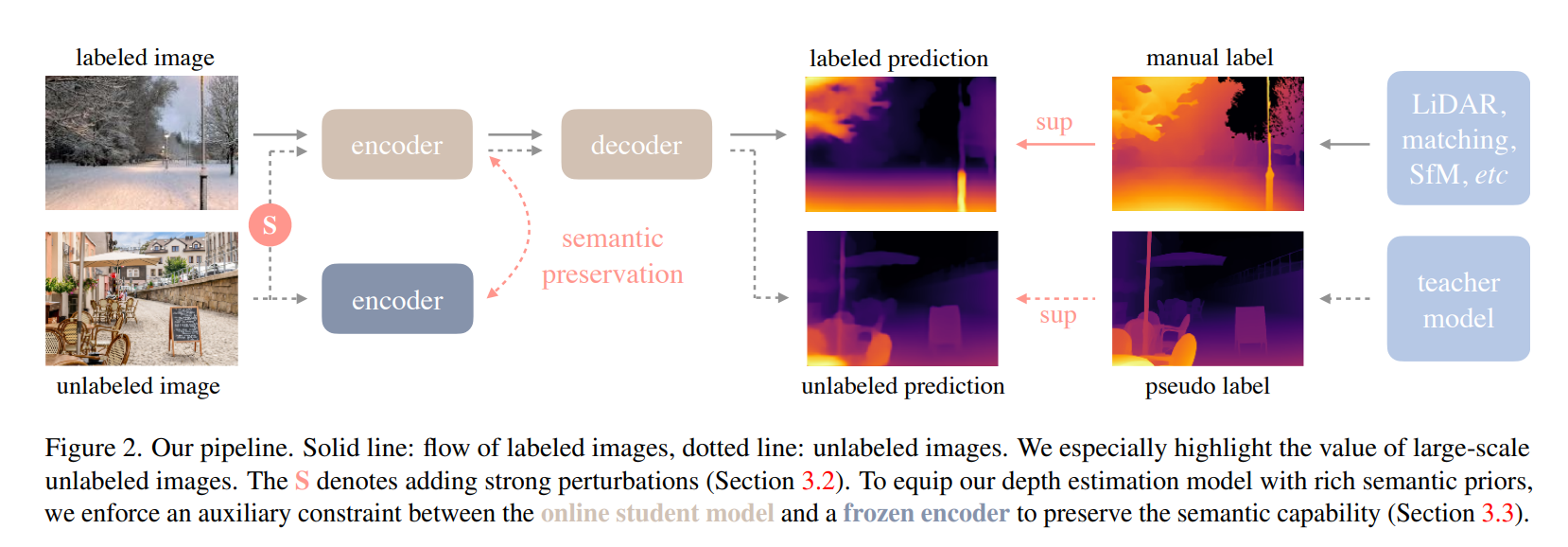
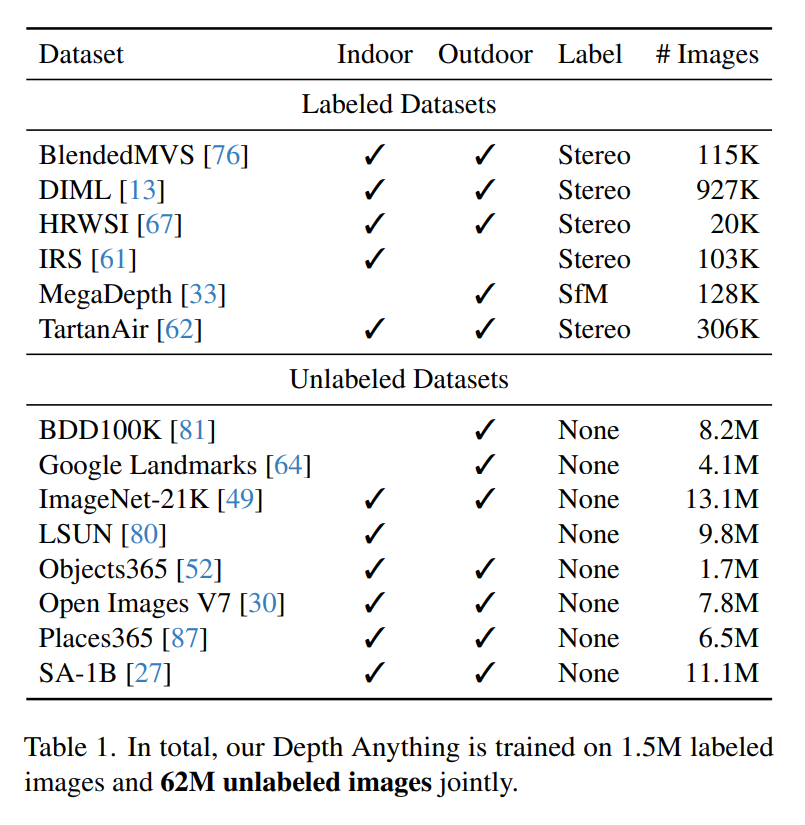
- Data
- 1.5M labeled images from 6 public datasets
- 62 M unlabeled images
- NYUv2 and KITTIは評価用に使わなかった
- Movies and WSVDはクオリティ低
- Learning Labeled Images
- Unlabeled images
- perturbations
- 主に2つ、シンプルながら強かった
- color distortion: color jittering + Gaussian blurring
- spatial distortion: CutMix
- Labeledで学習したあとだとunlabeledから学習するのが難しい
- TeacherとStudentが同じpre trainスタートだとよりその傾向になる
- Semantic-Assisted Depth estimation
- RAM [85] + GroundingDINO [37] + HQ-SAM [26] modelを使用
Experiment
- Zero-Shot Relative Depth Estimation
| Method |
Params |
KITTI |
|
NYUv2 |
|
Sintel |
|
DDAD |
|
ETH3D |
|
DIODE |
|
|
|
AbsRel |
$\delta_1$ |
AbsRel |
$\delta_1$ |
AbsRel |
$\delta_1$ |
AbsRel |
$\delta_1$ |
AbsRel |
$\delta_1$ |
AbsRel |
$\delta_1$ |
| MiDaS |
345.0M |
0.127 |
0.850 |
0.048 |
0.980 |
0.587 |
0.699 |
0.251 |
0.766 |
0.139 |
0.867 |
0.075 |
0.942 |
| Ours-S |
24.8M |
0.080 |
0.936 |
0.053 |
0.972 |
0.464 |
0.739 |
0.247 |
0.768 |
0.127 |
0.885 |
0.076 |
0.939 |
| Ours-B |
97.5M |
0.080 |
0.939 |
0.046 |
0.979 |
0.432 |
0.756 |
0.232 |
0.786 |
0.126 |
0.884 |
0.069 |
0.946 |
| Ours-L |
335.3M |
0.076 |
0.947 |
0.043 |
0.981 |
0.458 |
0.760 |
0.230 |
0.789 |
0.127 |
0.882 |
0.066 |
0.952 |
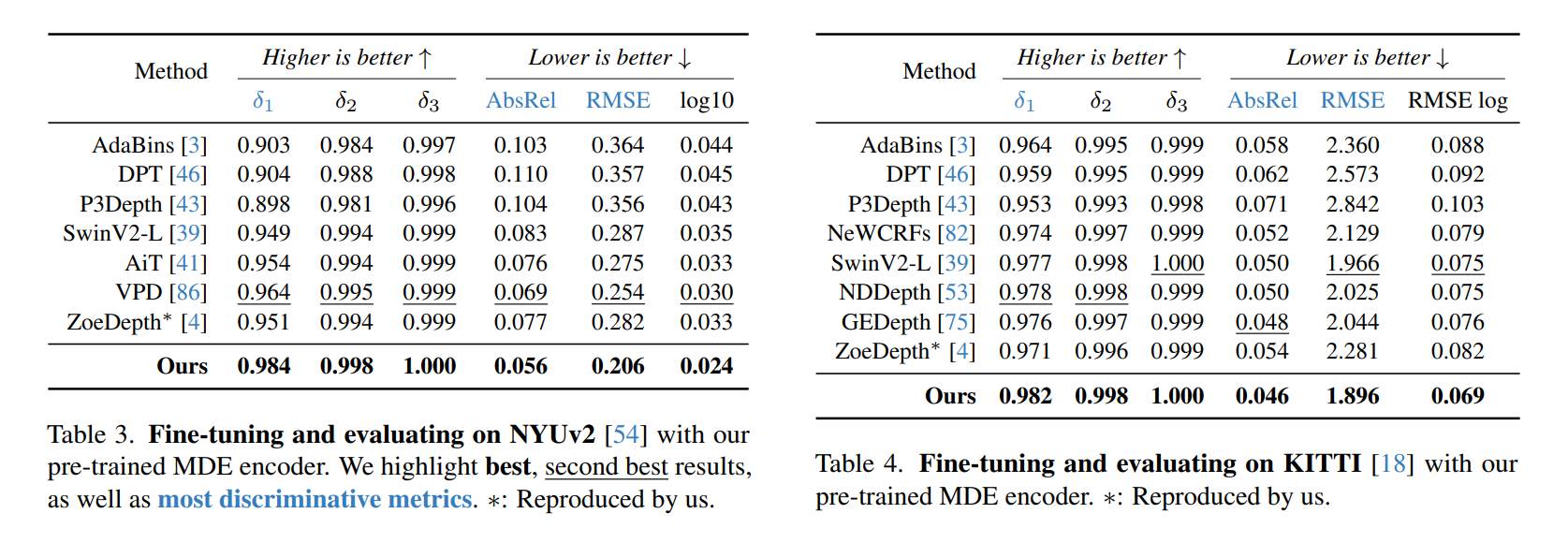
- Fine-tuning Absolute depth estimation
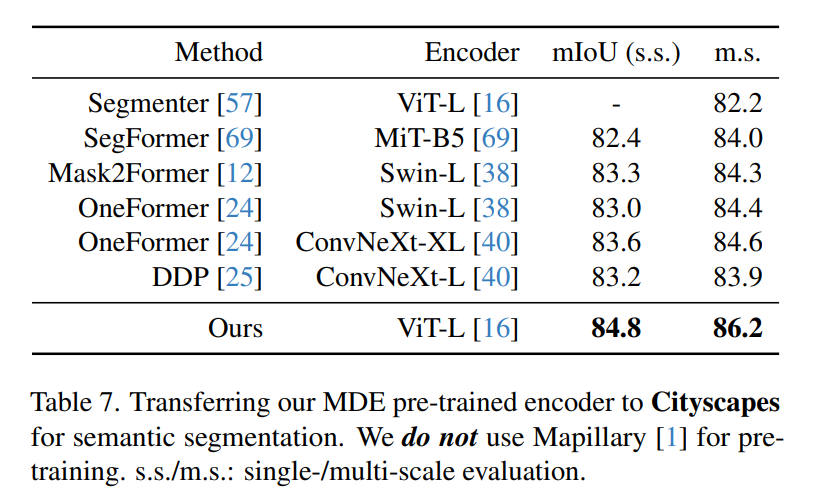
- Semantic segmentation for Cityscapes
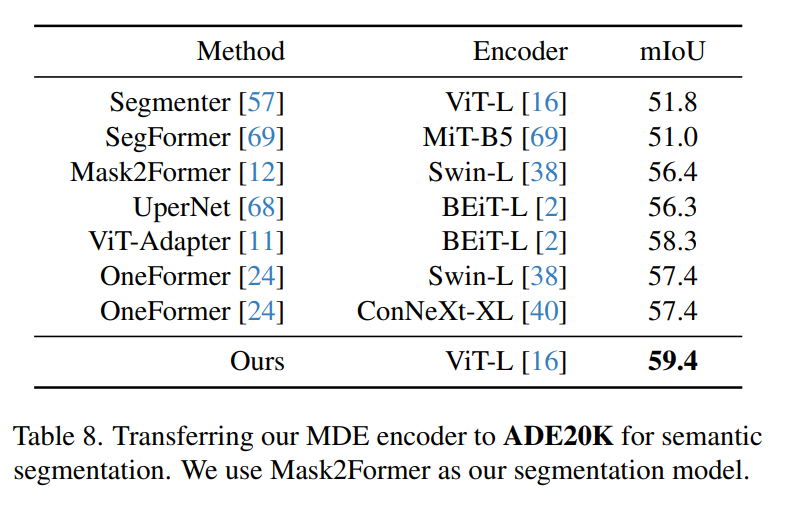
- Semantic segmentation for ADE20K
- Pre-trained models のInference time (ms)
| Model |
Params |
V100 |
A100 |
RTX4090 TensorRT |
| Depth-Anything-Small |
24.8M |
12 |
8 |
3 |
| Depth-Anything-Base |
97.5M |
13 |
9 |
6 |
| Depth-Anything-Large |
335.3M |
20 |
13 |
12 |
Discussion